

Elaboración de GPC en el SNS. Manual metodológico
Manual HTML

Nora Ibargoyen, Anna Selva, Iván Solà
6.1. Introducción
En este manual se propone la metodología desarrollada por el grupo GRADE (Grading of Recommendations Assesment, Development and Evaluation), al que nos referiremos como GRADE1,2, para evaluar la calidad de la evidencia y formular las recomendaciones de las Guías de Práctica Clínica (GPC) del Programa Nacional de GPC del SNS.
Las diferencias más relevantes entre GRADE (http://www.gradeworkinggroup.org/intro.htm) y otros sistemas previos en relación a la síntesis y evaluación de la calidad de la evidencia son principalmente las siguientes:
- La evaluación de la calidad de la evidencia se centra en el análisis por separado para cada desenlace de interés, que el grupo de trabajo habrá priorizado previamente en la fase de formulación de preguntas clínicas.
- Se amplía la habitual evaluación del riesgo de sesgo a otros factores como, por ejemplo, la consistencia de los resultados o su precisión.
- Se separa de forma explícita la definición de la calidad de la evidencia y de la fuerza de las recomendaciones.
En el apartado 6.2 se detalla el proceso para clasificar la calidad de la evidencia en relación a las preguntas terapéuticas o de prevención. El grupo de trabajo GRADE ha publicado una amplia serie de artículos3-19 y un manual electrónico2 en los que se amplían los contenidos de esta sección. En las diferentes secciones del capítulo se indican las publicaciones en las que se describe detalladamente cada uno de los aspectos discutidos.
El grupo GRADE ha desarrollado una plataforma electrónica denominada Guidelines Development Tool (http://gdt.guidelinedevelopment.org/), que facilita el proceso completo de la evaluación de la calidad de la evidencia, así como el resto de las etapas del proceso de formulación de recomendaciones. Se recomienda que los grupos de trabajo utilicen en el desarrollo de las recomendaciones de las guías del Programa del SNS esta plataforma y sus aplicaciones derivadas (por ejemplo, iSoF, iEtD). De esta forma se facilita, además del seguimiento de las recomendaciones en la elaboración, la homogeneidad entre los distintos productos elaborados por distintos grupos.
En los apartados 6.5 y 6.6 de este capítulo se realizan comentarios puntuales aplicables a otro tipo de preguntas. Por otro lado, GRADE propone una definición de la calidad de la evidencia diferente para su aplicación a las revisiones sistemáticas y a las guías de práctica clínica2. Para el propósito de este manual, las indicaciones irán dirigidas a la clasificación de la calidad de la evidencia en el contexto de la formulación de recomendaciones. La figura 6.1 muestra un esquema que sintetiza los contenidos del capítulo.
6.2. Evaluación de la calidad de la evidencia
6.2.1. Definición de la calidad de la evidencia
La calidad de la evidencia refleja la confianza que se puede depositar en los resultados de la literatura científica para apoyar una recomendación en particular2,17. Por este motivo algunas consideraciones sobre la calidad de la evidencia se deberán realizar en función del contexto particular para el que se está utilizando la literatura científica. En el proceso de clasificar la calidad de la evidencia se realiza una evaluación para cada desenlace de interés y un proceso de clasificación global entre todos los desenlaces que apoyen el proceso de decisión entre la evidencia y la recomendación.
La localización de guías de práctica clínica de calidad se ha visto favorecida en los últimos años por la aparición de repositorios, directorios y sitios web específicos, tanto nacionales como internacionales. Estas fuentes de información son creadas y mantenidas por entidades gubernamentales y asociaciones científicas o profesionales que compilan y clasifican las referencias bibliográficas y documentos pertinentes. Su ventaja es que facilitan a los usuarios una rápida recuperación de documentos relevantes, bien a través de sistemas de búsqueda básica o avanzada, o bien navegando entre categorías temáticas o de especialidades.
Aunque la calidad de la evidencia es un espectro continuo, GRADE propone una clasificación simple y explícita en cuatro grados1,17:

6.2.2. Factores que determinan la calidad de la evidencia
A continuación se describen cinco factores que pueden bajar la calidad de la evidencia y tres que pueden aumentarla2,17. Ver tabla 6.1.
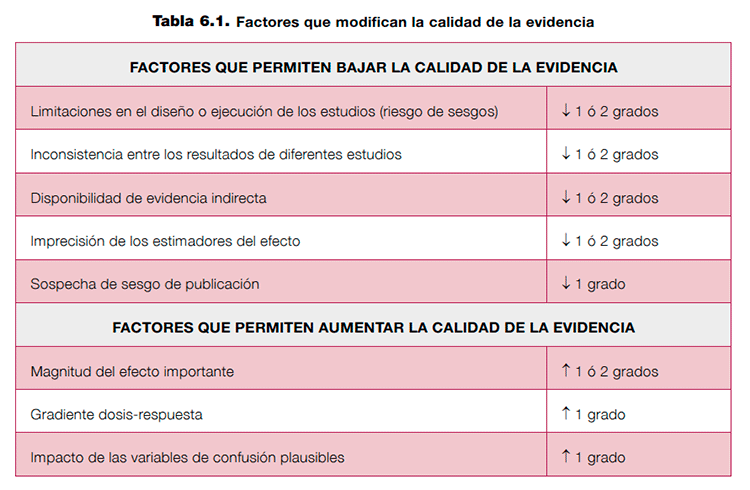
Estos factores no deben tomarse como elementos individuales que puedan sumarse o restarse para obtener una clasificación de la calidad. GRADE no propone esta clasificación como una serie de categorías discretas; cada categoría forma parte de un espectro continuo en el que se realizan juicios sobre cada factor en relación al resto2. Por este motivo es imprescindible que, al reflejar la clasificación de la calidad de la evidencia en los perfiles de evidencia, los autores sean explícitos en relación a los juicios que han llevado a una evaluación de la calidad en particular.
6.2.3. Consideraciones sobre el diseño de estudio
El diseño del estudio del que se obtienen los estimadores del efecto para apoyar una recomendación es determinante para iniciar la evaluación de la calidad de la evidencia. Para las preguntas clínicas de intervención, los ensayos clínicos ofrecen mejores estimadores del efecto que los estudios observacionales, del mismo modo que los estudios observacionales controlados ofrecen mejores estimadores que estudios no controlados.
GRADE propone, inicialmente, evaluar la calidad de la evidencia considerando los ensayos clínicos fuentes de calidad alta y los estudios observacionales sin limitaciones importantes, fuentes de calidad baja. A partir de este punto, la aplicación de los factores mencionados permitirán bajar o aumentar la calidad de la evidencia7-12.
Este planteamiento hace necesario algún comentario sobre otros diseños de estudio específicos2. Los ensayos clínicos no aleatorizados sin mayores limitaciones también pueden considerarse una fuente de evidencia de alta calidad, pero se debe bajar la calidad de la evidencia por limitaciones en el diseño (la falta de aleatorización aumenta el riesgo de selección).
Las series de casos o los estudios de caso único son estudios observacionales no controlados en los que la calidad de la evidencia debería bajarse automáticamente de baja a muy baja.
La opinión de experto no se considera un tipo de evidencia científica al que aplicar los factores modificadores de la calidad de la evidencia. La opinión de experto simplemente refleja la interpretación de los resultados de la evidencia, o de la ausencia de esta, en función de su conocimiento y experiencia. En cualquier caso en el que se refleje la opinión de experto en el desarrollo de una recomendación debe quedar explícita la manera en que se interpreta y cómo influye en el desarrollo de la recomendación17.
Las revisiones sistemáticas deben tomarse como fuentes de estudios que permiten conocer el conjunto de literatura científica que nos ofrece los mejores estimadores del efecto para desenlaces de interés específicos5. En las revisiones sistemáticas, la evaluación de los factores que afectan a la calidad de la evidencia debe realizarse sobre el diseño y las características de los estudios que incluye la revisión (ya sea un conjunto de estudios o de un único estudio).
6.2.4. Factores que permiten bajar la calidad de la evidencia en preguntas terapéuticas.
6.2.4.1. Limitaciones del diseño o ejecución de los estudios (riesgo de sesgo)
El sesgo es un error sistemático que afecta a los resultados o inferencias que se derivan de un estudio. Influye en cualquier dirección, de manera que puede llevar a la subestimación o sobreestimación del efecto de una intervención20. Por este motivo, las limitaciones en el diseño o ejecución de un estudio pueden sesgar los estimadores sobre el efecto de una intervención y por tanto limitar la confianza en sus resultados7.
Existen múltiples herramientas para evaluar el riesgo de sesgo tanto en ensayos clínicos como en estudios observacionales. En el caso de los ensayos clínicos, la herramienta para evaluar el riesgo de sesgo propuesta por la Colaboración Cochrane20 (Ver anexo 6.1) permite realizar una evaluación explícita sobre los aspectos que han demostrado tener un mayor impacto sobre los estimadores del efecto de una intervención. Esta herramienta es la de elección para evaluar las limitaciones de un ensayo clínico. La tabla 6.2 resume brevemente los aspectos valorados con esta herramienta.
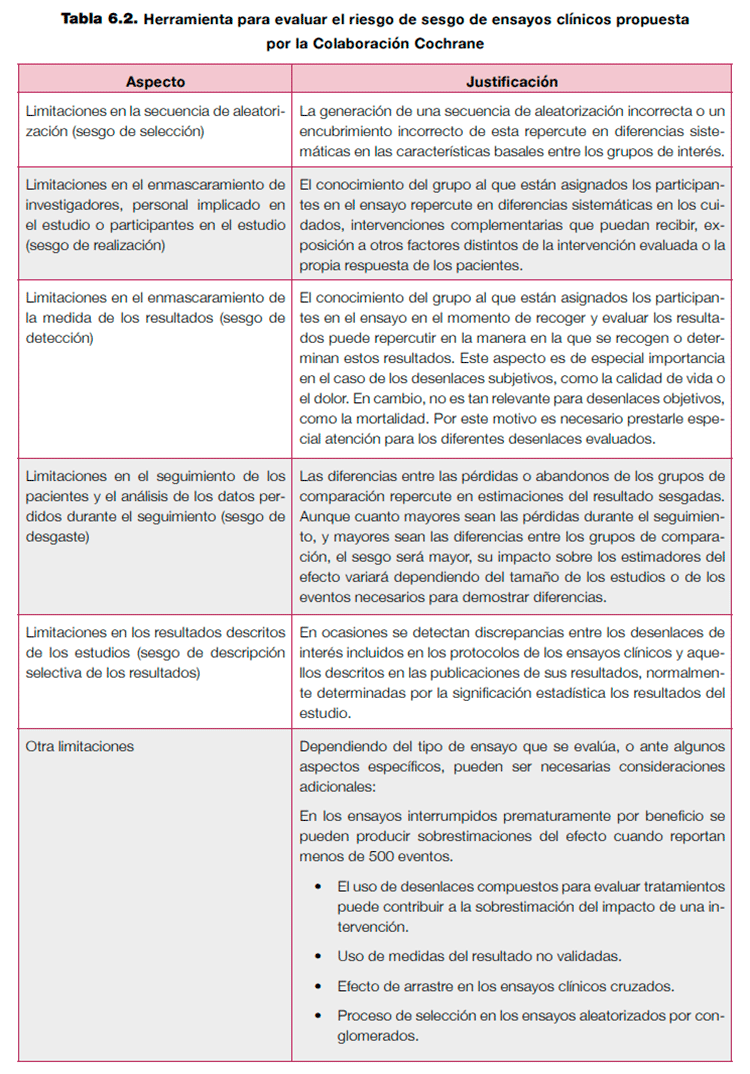
Aunque algunos de estos aspectos son sencillos de evaluar, es importante insistir en la necesidad de hacer juicios explícitos de los motivos que llevan a modificar la calidad de la evidencia para lograr transparencia sobre los motivos que llevan a bajar la calidad. Por ejemplo, el único ensayo clínico que evalúa el impacto del eculizumab en pacientes con hemoglobinuria nocturna paroxística ofrece resultados sobre la calidad de vida y la fatiga en estos pacientes21. A pesar de que los desenlaces se evaluaron con escalas validadas, la recogida de resultados no fue enmascarada y, además, un porcentaje muy importante de pacientes que recibieron placebo abandonaron el tratamiento por no apreciar beneficio. Estos dos aspectos combinados pueden llevar a bajar la calidad de la evidencia por limitaciones en el diseño. Cuando se valora el enmascaramiento es muy importante tener en cuenta la naturaleza del desenlace de interés. De este modo, una revisión sobre la eficacia y seguridad de la termoplastia en pacientes con asma bajó la calidad de la evidencia en los desenlaces principales de interés, ya que los estudios que incluyó no estaban cegados y la medida principal de resultado (calidad de vida, control sintomático del asma) era subjetiva, mientras que este motivo no se aplicó en desenlaces más objetivos, como las hospitalizaciones motivadas por efectos adversos22.
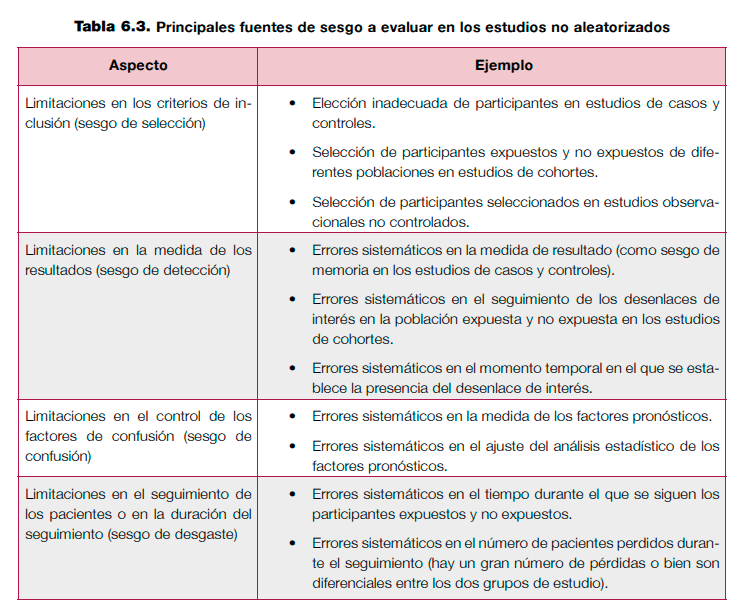
La evaluación del riesgo de sesgo en los estudios no aleatorizados plantea más retos, debido a la dificultad para determinar el diseño de estudio en algunos casos y a la multitud de herramientas disponibles para evaluarlos23. Una revisión sistemática evaluó las propiedades de estas herramientas, destacando la utilidad de las escalas Downs y Blackyy Newcastle-Ottawa24. Sin embargo la aplicación práctica de la escala de Downs y Black25 es dificultosa para evaluar diseños de estudio como los de casos y controles, y puede requerir de conocimientos epidemiológicos avanzados para su uso correcto26. Por su parte, la escala Newcastle-Ottawa27 también puede presentar dificultades para su adaptación a algunos diseños de estudio, ya que está diseñada específicamente para estudios de cohortes y casos y controles23. Actualmente, la Colaboración Cochrane trabaja en el desarrollo de una nueva herramienta (ACROBAT-NRSI)28. A efectos prácticos, la tabla 6.3 resume las principales fuentes de sesgo que hay que evaluar en los estudios no aleatorizados (ver anexo 6.2).
Puede ser complejo valorar globalmente el riesgo de sesgo de un conjunto de estudios con diferentes limitaciones y que aportan estimadores para un desenlace de interés en concreto. GRADE propone las siguientes directrices2:
- El riesgo de sesgo global para un conjunto de estudios no es el promedio de sus principales limitaciones. Es preferible realizar un juicio razonado del posible impacto de los diferentes estudios sobre cada uno de los desenlaces de interés, prestando atención a los estudios con menor riesgo de sesgo. En este sentido, se debe valorar la medida en que cada estudio contribuye en la estimación del efecto (por ejemplo, los estudios con un mayor tamaño de la muestra aportan un mayor número de eventos a un análisis y, por tanto, su riesgo de sesgo puede ser determinante).
- Se puede aplicar un enfoque menos conservador y calificar como baja la calidad de la evidencia solo cuando haya un riesgo de sesgo sustancial en los estudios disponibles que lo justifique. También es importante valorar el riesgo de sesgo en el contexto de otras limitaciones, bajando la calidad de la evidencia por el factor al que se atribuya una mayor importancia. Este juicio obliga a justificar de manera explícita en los perfiles de evidencia la decisión que se ha tomado para bajar la calidad de la evidencia y a señalar a qué factor se ha otorgado más peso en la decisión.
- Con un criterio pragmático, se podría evaluar la calidad de la evidencia a partir de aquellos estudios con un menor riesgo de sesgo, sin bajar la calidad de la evidencia por este motivo, y continuar aplicando el resto de factores.
6.2.4.2. Inconsistencia entre los resultados de diferentes estudios
La inconsistencia se refiere a la variabilidad o heterogeneidad de los resultados entre los estudios disponibles para un determinado desenlace de interés. Es necesario valorar si existe alguna explicación plausible para la variabilidad, siempre y cuando se identifique que existe heterogeneidad y, en caso de no identificarla, bajar la calidad de la evidencia por inconsistencia8.
Las diferencias entre los estimadores de los estudios podrían explicarse por diferencias entre las poblaciones de interés (pacientes con diferentes riesgos basales), las intervenciones evaluadas (diferencias en la duración o la complejidad de la intervención), los desenlaces (diferentes medidas de los resultados) o el diseño de los estudios (diferente riesgo de sesgo entre los estudios). Cuando se dispone de una explicación para los pacientes, intervenciones o desenlaces, la calidad de la evidencia puede evaluarse para diferentes tipos de pacientes o intervenciones. Cuando la fuente de variabilidad se debe al diseño de los estudios, la evaluación de la calidad de la evidencia puede centrarse en aquellos con un menor riesgo de sesgo.
Las situaciones más comunes que permiten bajar por inconsistencia la calidad de la evidencia son las siguientes8:
- Existe una amplia variabilidad en los estimadores del efecto entre los diferentes estudios disponibles para apoyar la recomendación.
- No hay solapamiento entre los límites de los intervalos de confianza de los estudios, o hay poco solapamiento.
- El test de heterogeneidad de un metanálisis, que contrasta la hipótesis sobre la existencia de heterogeneidad de la magnitud del efecto entre los estudios, muestra un valor de P bajo (generalmente por debajo de 0,1029).
- El valor del estadístico I2 obtenido a partir del metanálisis. No se puede establecer un umbral fijo que determine a partir de qué valor de I2 se puede considerar que la variabilidad afecta la confianza en los estimadores del efecto, y dependerá del juicio que se haga en cada caso. Como referencia aproximada, valores de I2 por debajo del 40% pueden considerarse bajos; entre el 30% y el 60% pueden considerarse moderados; entre el 50% y el 90% pueden considerarse sustanciales; y entre el 75% y el 100% pueden considerarse importantes29.
Teniendo en cuenta las limitaciones de interpretar de manera aislada el resultado de un test estadístico para determinar el impacto de la heterogeneidad en la confianza de los resultados, siempre es necesario valorar las diferencias entre los estimadores y el grado de solapamiento de sus intervalos de confianza. Es posible que en ocasiones se identifique la existencia de heterogeneidad a partir de los resultados de las pruebas estadísticas mencionadas, pero que se encuentre una explicación a esta variabilidad al analizar los estudios al detalle (por ejemplo, por la presencia de diferencias en los participantes incluidos en los diferentes estudios), razón por la cual no se disminuiría la calidad de la evidencia. En otras publicaciones sobre GRADE se profundiza en mayor medida en diferentes situaciones en las que considerar aspectos sobre la inconsistencia2,8. Se insiste en que la evaluación de la inconsistencia debe considerar, además de las pruebas estadísticas disponibles para el análisis de la heterogeneidad, aspectos como la dirección de los estimadores del efecto y su solapamiento. Esto permitiría realizar una valoración más exhaustiva de la variabilidad entre los estudios disponibles. Por ejemplo, en una revisión sistemática los nueve ensayos clínicos que evaluaron el uso de flavonoides para disminuir la sintomatología de las hemorroides mostraban estimadores del efecto muy dispares, con intervalos de confianza que se solapaban poco, hecho que se reflejó en un valor de I2 considerable (65%)30. Aunque los autores no pudieron explicar la fuente de variabilidad, la decisión de bajar la calidad de la evidencia en esta situación no sería clara, teniendo en cuenta, por ejemplo, que todos los ensayos clínicos, salvo uno, mostraron un efecto favorable a los flavonoides. Este escenario sugiriere que los resultados disponibles en la literatura son consistentes y que tan solo existe una variabilidad en la magnitud del efecto.
Como se ha señalado, en ocasiones la variabilidad en los resultados puede explicarse por diferencias entre distintos subgrupos. Mientras que los estimadores en términos de riesgos relativos obtenidos en la literatura suelen ser constantes entre estos subgrupos, puede existir una variación considerable en las diferencias de riesgo (reducción absoluta del riesgo) entre los subgrupos, debido a que los pacientes pueden tener un amplio rango de riesgos basales respecto a los principales desenlaces de interés.
En aquellas ocasiones en las que se identifiquen subgrupos diferenciados claramente por su riesgo basal puede ser preferible plantear diferentes recomendaciones para cada subgrupo, en lugar de bajar la calidad de la evidencia por la inconsistencia identificada en los estimadores relativos del efecto.
Esta situación plantea la necesidad de valorar la credibilidad de los subgrupos. Por este motivo se han desarrollado unos criterios para valorar si los subgrupos muestran resultados fiables31-33, que se presentan en la siguiente tabla.

Estos criterios no son una escala para puntuar cada una de las preguntas, son directrices para evaluar críticamente aquellos aspectos que pueden tener un impacto más relevante en la definición de subgrupos. Por otra parte, la valoración de estos aspectos no plantea una respuesta categórica a los diferentes criterios, sino que requiere de un juicio en un espectro continuo, que debe razonarse de manera explícita en el momento de completar los perfiles de evidencia y justificar la clasificación de la calidad de la evidencia.
En una guía se planteó si la administración perioperatoria de fluidos guiada por objetivos hemodinámicos tiene algún efecto en la morbilidad y mortalidad de los pacientes sometidos a cirugía no cardiaca34. En el caso de la mortalidad, al analizar conjuntamente todos los pacientes incluidos en los 35 ensayos clínicos que comparan la realización de fluidoterapia guiada por objetivos frente a la fluidoterapia convencional, no se observó un efecto estadísticamente significativo (310 eventos, RR 0,80; IC95% 0,64 a 1,00). Sin embargo, los pacientes incluidos presentaban importantes diferencias en cuanto a su riesgo basal. Se realizó un análisis de subgrupos según el riesgo basal de los participantes y se observó que cuando el riesgo basal era menor del 10% no había diferencias entre la aplicación de una fluidoterapia guiada por objetivos y la convencional. Sin embargo, en los pacientes con un riesgo basal de mortalidad del 10% o superior, la fluidoterapia guiada por objetivos redujo un 59% el riesgo de mortalidad (10 ensayos, 105 eventos, RR 0,41; IC95% 0,37 a 0,62). En este caso, se consideró un efecto de subgrupos real, ya que no pudo explicarse por el azar (test para diferencia de subgrupos: p=0,002), era plausible desde el punto de vista fisiopatológico, y ya se había reportado un efecto similar en otras revisiones sistemáticas. Esta diferencia de subgrupos llevó a realizar una recomendación débil a favor de la fluidoterapia guiada por objetivos para la mayoría de los pacientes y una recomendación fuerte a favor para los pacientes de alto riesgo.
6.2.4.3. Disponibilidad de evidencia indirecta
Es necesario valorar la aplicabilidad de los resultados disponibles en la literatura para apoyar una recomendación. Cuando se disponga de estudios realizados en una población diferente a la definida en la pregunta PICO a la que se desea aplicar la evidencia, o que hayan evaluado una intervención que difiere en algunos aspectos a la de interés para la pregunta o que hayan medido desenlaces de interés diferentes a los del contexto en el que se implantarán las recomendaciones, la confianza en estos estudios será menor y por lo tanto deberá bajarse la calidad de la evidencia por su carácter indirecto. Otra fuente de evidencia indirecta es la ausencia de estudios que comparen de manera directa dos intervenciones de interés para formular una recomendación9.
Se puede considerar evidencia indirecta la disponibilidad de estudios con participantes con características diferentes a las de la población a la que se dirige la guía de práctica clínica. Aunque las revisiones sistemáticas acostumbran a restringir la población de interés en sus criterios de inclusión, hay ocasiones en las que las recomendaciones deben basarse en estudios originales con participantes diferentes a los de interés o en las que la literatura relevante no ofrece información específica sobre la población de interés para la pregunta clínica de la guía. Generalmente, los ensayos clínicos excluyen a los pacientes que presentan comorbilidad o pluripatología, lo que impide disponer de estudios en los que se hayan evaluado adecuadamente las intervenciones que precisan este tipo de pacientes. En estos casos, a la hora de valorar la evidencia disponible se deberá evaluar detalladamente la naturaleza directa o indirecta de la evidencia. El capítulo 9, “Abordaje de la comorbilidad y la pluripatología” trata con mayor detalle este aspecto.
Por ejemplo, una pregunta clínica puede plantear si, entre otros cambios en el estilo de vida en pacientes con enfermedad renal crónica, la reducción del hábito tabáquico puede retrasar la progresión de la enfermedad. Aunque no existen ensayos clínicos que hayan comparado el impacto de intervenciones para dejar de fumar en la progresión de la enfermedad de estos pacientes, existen varios estudios observacionales que han mostrado que fumar acelera la progresión de la enfermedad renal. Teniendo en cuenta estos resultados, un grupo de trabajo podría asumir que los pacientes con este problema de salud se beneficiarán de los programas de deshabituación que han mostrado eficacia para otras poblaciones, pero esta decisión implicaría bajar la calidad de la evidencia por evidencia indirecta.
En ocasiones, la fuente de evidencia indirecta es la intervención de interés. De este modo, una pregunta clínica sobre la eficacia del cribado de cáncer de colon con colonoscopia puede considerar la posibilidad de bajar la calidad de la evidencia en el caso de usar los resultados de un ensayo clínico que evalúe el impacto de un cribado de sangre oculta en heces9. Este aspecto es relevante cuando una misma intervención requiera una aplicación diferente dependiendo del contexto en el que se desee implantar la prestación. Muchos estudios que evalúan intervenciones complejas pueden plantear una situación en la que se deba valorar disminuir la calidad de la evidencia.
Otra fuente de evidencia indirecta importante puede ser la disponibilidad de desenlaces intermedios, o diferentes a los planeados, para apoyar las recomendaciones. Si solamente se dispone de desenlaces intermedios, siempre deberá disminuir la calidad de la evidencia por evidencia indirecta. La decisión de bajar un nivel o dos la calidad de la evidencia dependerá de la relación plausible que exista entre el desenlace intermedio y el desenlace de interés. La tabla 6.5 muestra ejemplos de desenlaces intermedios y sus correspondientes desenlaces importantes para la toma de deisiones2.
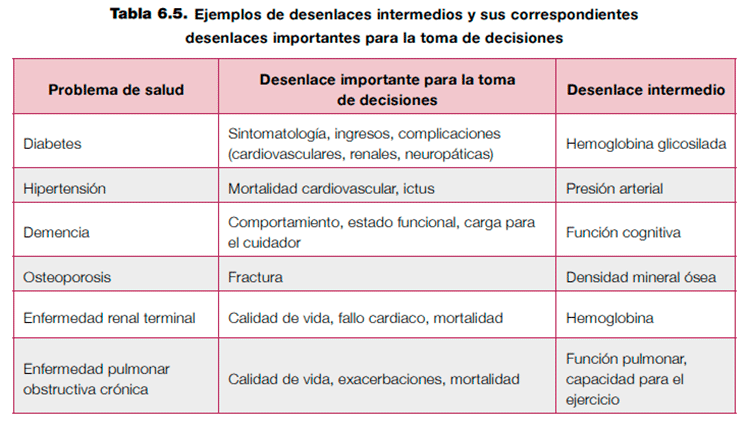
Por ejemplo, una revisión sistemática no encontró estudios que valoraran la asociación entre la dispensación de parafernalia estéril o segura (diferente a jeringuillas) a usuarios de drogas y los casos incidentes de infección por el virus de la hepatitis C, pero algunos estudios han mostrado que los usuarios de drogas que usan de manera frecuente parafernalia estéril, frente a los usuarios que la usan de manera infrecuente, muestran una menor prevalencia de infección por el virus35. Una recomendación basada en los resultados de estos desenlaces intermedios debería bajar la calidad por evidencia indirecta.
Por último, es habitual que no se dispongan de estudios que han comparado de manera directa dos tratamientos de interés. En alguna ocasión es posible que ambos tratamientos se hayan comparado en dos estudios independientes con un comparador común; por ejemplo, con un placebo. La validez de estas comparaciones depende de la asunción de que los estudios que han evaluado las intervenciones de interés tienen un diseño sin mayores sesgos y con características similares en sus poblaciones, intervenciones y desenlaces2.
Este hecho implica que, cuando se formulen recomendaciones apoyadas en estimadores obtenidos de comparaciones indirectas, se deba bajar la calidad por evidencia indirecta. Una revisión que comparó dos dosis de aspirina para prevenir la oclusión del injerto en pacientes sometidos a cirugía de revascularización coronaria incluyó dos ensayos que compararon una dosis media con placebo y tres ensayos que compararon una dosis baja con placebo36. Aunque una comparación indirecta de los resultados combinados de los estudios mostraba un mayor efecto de las dosis medias frente a las bajas, la confianza en estos resultados es menor que la que se obtendría de un ensayo que comparara ambas dosis de manera directa.
Dado que es habitual que no se disponga de estudios que hayan comparado de manera directa intervenciones relevantes, cada vez se han popularizado más los metanálisis en red (network meta-analysis). Estos estudios permiten obtener estimadores del efecto de distintos tratamientos a partir de comparaciones directas, indirectas o mixtas teniendo en cuenta los ensayos disponibles que han evaluado los diferentes tratamientos de interés37. El uso de estos estimadores indirectos obliga a valorar si es necesario bajar la calidad de la evidencia. La valoración de estos estudios es compleja y el desarrollo de directrices para evaluar este tipo de estudios está aún en proceso, pero ante la necesidad de evaluación de este tipo de evidencia, el GEG puede referirse a las directrices GRADE para evaluar la calidad cuando se desarrolla un estudio de estas características38 o a una guía de lectura crítica de este tipo de estudios39. Por ejemplo en un metanálisis en red de 12 antidepresivos de nueva generación40 se identificaron 117 ensayos de los que se ofreció poca información sobre la gravedad de los pacientes o posibles cointervenciones. Todos los ensayos incluidos en el análisis aportaron datos sobre al menos una comparación directa, con un total de 70 comparaciones entre antidepresivos. Los resultados mostraron diferencias significativas en la respuesta al tratamiento en solamente tres de las comparaciones. La poca especificidad del desenlace de interés y el poco poder del análisis realizado en el metanálisis llevaría a bajar la calidad de la evidencia.
6.2.4.4. Imprecisión de los estimadores del efecto
La precisión de un estimador del efecto se define por el intervalo de confianza alrededor de la medida con la que se presentan los resultados y está condicionada en parte por el tamaño de la muestra del estudio del que se obtiene el estimador. La manera más común de imprecisión se aprecia en aquellos estudios con un tamaño de muestra pequeño, que, en consecuencia, muestran pocos eventos y estimadores del efecto con intervalos de confianza amplios.
La valoración de la amplitud del intervalo de confianza puede estar sujeta a consideraciones sobre el impacto de un estimador del efecto en relación a otro, de la relevancia clínica de los extremos del intervalo o de si el estimador está basado en un tamaño muestral suficiente (optimal information size)10. Este último concepto nos remite al número total de pacientes que deberían haberse incluido en los diferentes estudios que han aportado datos a una comparación en concreto en la revisión sistemática para mostrar una diferencia significativa, de una manera similar a la del cálculo del tamaño de la muestra convencional en un ensayo clínico41.
En términos generales, los intervalos de confianza muestran el impacto del error aleatorio sobre la confianza en los estimadores del efecto, ya que muestra el rango de resultados en los que es posible que esté representado el efecto real de una intervención.
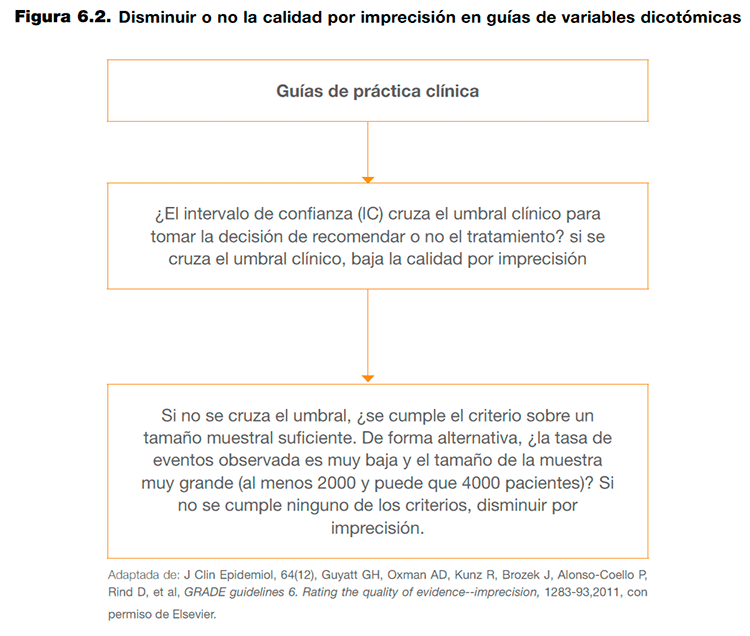
El problema que se plantea al valorar la imprecisión es la necesidad de determinar en qué situaciones los intervalos de confianza muestran suficiente incertidumbre como para bajar la calidad de la evidencia. Teniendo en cuenta que en el caso de las guías de práctica clínica se valoran un conjunto de desenlaces de interés, la decisión de bajar la calidad de la evidencia por imprecisión depende del umbral que determina la diferencia mínima relevante para los pacientes y del balance entre efectos deseables e indeseables de una intervención. La determinación de este umbral es una decisión que implica un juicio razonado y que debe reflejarse de manera explícita en los perfiles de evidencia2. En el caso de variables dicotómicas, los pasos que se han sugerido para determinar si se debe bajar la calidad de la evidencia por imprecisión se detallan en el Anexo 6.3.
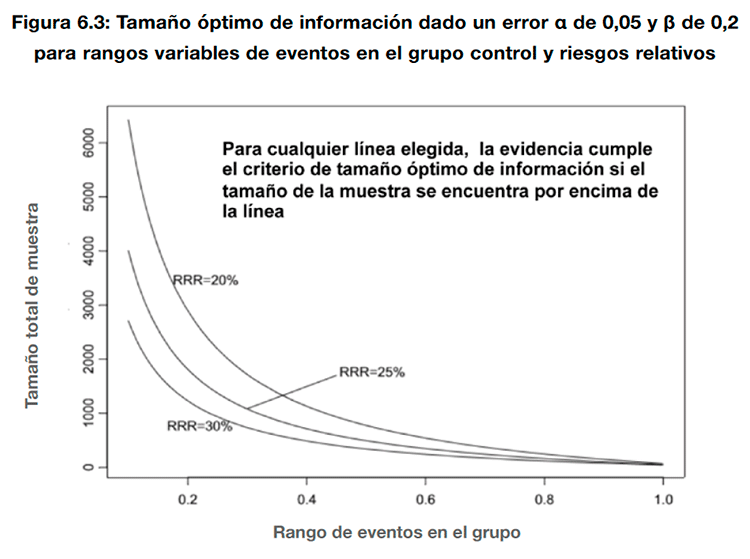
Las consideraciones para bajar la calidad de la evidencia por imprecisión cuando se valoran desenlaces continuos siguen el mismo razonamiento que en el caso de los desenlaces dicotómicos. Se debería bajar la calidad de la evidencia si se considera que el intervalo de confianza cruza el umbral que determina la diferencia mínima relevante para los pacientes. En caso de que el intervalo de confianza no cruzara este umbral, debería conocerse el tamaño óptimo de información para el desenlace. En este caso, la calidad de la evidencia debería bajarse por imprecisión cuando el número total de pacientes o eventos incluidos en una revisión sistemática es menor al que se obtendría de un cálculo del tamaño de la muestra de un ensayo clínico convencional (hay disponibles diversas calculadoras electrónicas para realizar este cálculo. Como alternativa, GRADE propone una figura que establece una correspondencia simulada entre el tamaño de la muestra necesario para obtener un número determinado de eventos10. La figura se ha diseñado asumiendo un error α del 0,05 y β del 0,2 para reducciones relativas del riesgo (RRR) del 20%, 25% y 30%, y un rango variable de riesgos para el grupo control (del 0,2 a 1,0). Con estos supuestos, con un riesgo en el grupo control del 0,2% y una RRR del 25%, el tamaño óptimo de información obtenido sería de 2000 pacientes (ver figura 6.3).
Como ejemplo, en una revisión se mostró que los corticoesteroides disminuyen el tiempo de hospitalización debido a exacerbaciones en pacientes con EPOC, aunque el extremo inferior del intervalo de confianza sugiere una reducción muy poco relevante para los pacientes42 (1,42 días; IC95% 0,65 a 2,20), hecho que justifica que la calidad de la evidencia baje por imprecisión.
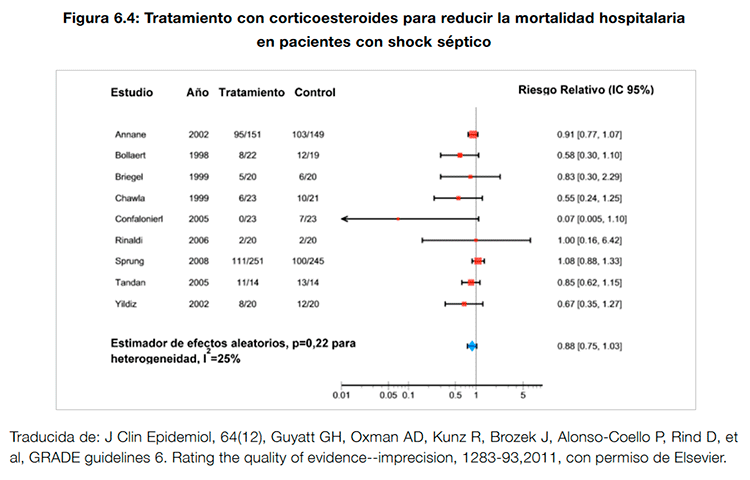
En un artículo del grupo GRADE10 se señala como ejemplo un metanálisis de ensayos sobre el uso de esteroides en pacientes con shock séptico en el que murieron 511 pacientes. El intervalo de confianza para el estimador del efecto (de 0,75 a 1,03) se superpone al riesgo relativo (RR) de 1 (no efecto), lo que sugiere que una recomendación contra el uso de los esteroides sería lo adecuado. Sin embargo, el límite del intervalo consistente con el máximo efecto sugiere que los esteroides podrían reducir el RR de muerte hasta en un 25%, por lo que la evidencia en contra del uso de esteroides podría ser calificada como moderada y no como alta (ver figura 6.4).
Existe gran cantidad de literatura que ha evaluado las diferencias clínicas mínimamente importantes para diferentes desenlaces continuos, principalmente para escalas de medida o cuestionarios43-45. Una búsqueda de estos estudios puede ayudar a establecer los umbrales para valorar la imprecisión en los desenlaces continuos.
Una búsqueda de estas características permitió establecer unos umbrales para valorar la imprecisión de los estimadores del efecto sobre la fatiga en una revisión sobre el eculizumab en pacientes con hemoglobinuria nocturna paroxística46. A través de la literatura se identificaron las diferencias clínicas mínimas para el instrumento con el que se midió la fatiga en el único ensayo clínico que incluyó la revisión47.El intervalo de confianza del estimador para este desenlace no cruzaba el umbral identificado en la literatura y, por tanto, no se bajó la calidad de la evidencia por imprecisión.
6.2.4.5. Sesgo de publicación
El sesgo de publicación se produce cuando se publican selectivamente los resultados de los estudios repercutiendo en una estimación inadecuada del efecto real de una intervención48. A pesar de que en las revisiones sistemáticas siempre se realiza un esfuerzo por identificar todos los estudios elegibles para responder a su pregunta clínica, en ocasiones es difícil acceder a los datos de estudios que no se han publicado, normalmente por presentar resultados negativos. Este sesgo no debe confundirse con el sesgo de descripción selectiva de los resultados, valorado en las limitaciones del diseño de los estudios11.
Se han identificado diversas situaciones en las que es más probable que exista sesgo de publicación. Las revisiones que incluyen varios estudios con una muestra pequeña pueden presentar más probabilidades de sesgo de publicación. Además, si estos estudios son financiados por la industria, entonces la conjunción de ambos elementos genera alta sospecha de la existencia de sesgo de publicación. Los estudios con una muestra más grande tienden a mostrar más eventos y tienen más posibilidades de ser publicados independientemente de sus resultados. Se ha estimado que existen discrepancias en el 20% de ocasiones en las que se comparan los resultados de revisiones sistemáticas de estudios pequeños con los de estudios publicados posteriormente con una muestra mayor. Esta discrepancia podría explicarse por el sesgo de publicación49,50. La decisión de bajar la calidad de la evidencia por sesgo de publicación ante la disponibilidad de múltiples estudios con una muestra pequeña se refuerza cuando varios de estos estudios hayan sido patrocinados por la industria o los investigadores tengan graves conflictos de interés. Aunque menos frecuentemente, en ocasiones se retrasa la publicación de los estudios por resultados negativos o poco satisfactorios11. Por ejemplo, un estudio analizó 74 ensayos sobre antidepresivos enviados para su consideración a la FDA, con una muestra de menos de 200 pacientes incluidos de media51. De los 38 estudios valorados positivamente por la FDA, 37 fueron publicados, mientras que solamente 14 de los 36 estudios valorados negativamente llegaron a publicarse.
En el proceso de valoración del sesgo de publicación, los grupos de trabajo pueden valorar las múltiples aproximaciones estadísticas que existen para cuantificar este fenómeno, que, pese a algunas limitaciones, pueden ofrecer una aproximación del impacto de este sesgo sobre los estimadores del efecto11,48. En cualquier caso, GRADE reconoce la dificultad de valorar este aspecto y todavía más la de establecer un umbral a partir del cual el sesgo de publicación puede tener un impacto sobre la confianza en los estimadores del efecto, motivo por el cual se sugiere que como máximo se baje un nivel la calidad de la evidencia por esta razón.
6.2.5. Factores que permiten aumentar la calidad de la evidencia en preguntas terapéuticas
Cuando se utilizan los resultados de estudios observacionales para evaluar el impacto de una intervención, sus estimadores del efecto deben interpretarse con más precaución que en el caso de los ensayos clínicos, debido a que el sesgo es potencialmente mayor (por ejemplo, con aspectos relacionados con el sesgo de selección)23. Este es un motivo por lo que el sistema GRADE propone que cuando se utilice este tipo de estudios para evaluar la eficacia de las intervenciones, se considere que la evidencia es de baja calidad. En contadas ocasiones, la confianza en los resultados de los estudios observacionales aumenta por alguna de las razones que se discuten en este apartado.
Es imprescindible tener en cuenta que, antes de valorar los aspectos que permiten aumentar la calidad de la evidencia, hay que asegurarse de que no hay ninguna razón para bajar la calidad de la evidencia por cualquiera de los factores que se han expuesto más arriba2,12.
6.2.5.1. Magnitud del efecto importante
Cuando los estimadores presentan efectos importantes o muy importantes la confianza en estos resultados puede aumentar (ver tabla 6.6).

La decisión de aumentar la calidad de la evidencia por este motivo se refuerza en situaciones en las que el impacto de la intervención es rápido, se observa un efecto consistente entre los participantes en los estudios, la intervención revierte el curso clínico del problema de salud, o se dispone de evidencia indirecta consistente. Por ejemplo, una revisión sistemática de estudios observacionales sobre la posición de los lactantes en la cuna a la hora de dormir para evitar el síndrome de muerte súbita mostró una reducción importante del riesgo para la posición boca arriba con un OR de 4,1 (IC95% 3,1 a 5,5)52. En este caso, se podría elevar la calidad de la evidencia por una magnitud del efecto importante. Por otro lado, en un estudio epidemiológico sobre el uso de dispositivos intrauterinos y su impacto sobre la infección por el virus del papiloma humano y el riesgo de desarrollar cáncer de cérvix, se observó una fuerte asociación entre el uso de los dispositivos y la reducción del riesgo de cáncer de cérvix (OR 0,55; IC95% 0,42 a 0,70)53. Este caso no cumple con los criterios comentados para aumentar la calidad de la evidencia por magnitud del efecto importante.
6.2.5.2. Gradiente dosis–respuesta relevante
La identificación de un gradiente dosis-respuesta es uno de los criterios clásicos para establecer una relación de causa-efecto54. Por tanto, cuando se detecta un gradiente de este tipo, la confianza en los resultados puede aumentar. Por ejemplo, existe un gradiente dosis-respuesta asociado al momento en el que se administran antibióticos en los pacientes con sepsis e hipotensión55, ya que se ha observado un importante aumento en la mortalidad por cada hora que se retrasa la administración del tratamiento.
6.2.5.3. Impacto de las variables de confusión plausibles
En los estudios observacionales rigurosos se controlan los factores pronósticos conocidos asociados con el desenlace de interés. Ocasionalmente, las variables de confusión no contempladas en un análisis ajustado en un estudio observacional, aunque tenga un diseño riguroso, pueden sesgar la estimación del efecto de la intervención o exposición de interés. Esta situación podría llevar a no apreciar un efecto existente de la intervención por la falta de control de estas variables.
Las variables de confusión pueden reducir o aumentar el impacto de la intervención o exposición de interés. Por ejemplo, varios estudios observacionales han mostrado que el uso del preservativo por parte de varones que tienen sexo con varones reduce el riesgo de infección por VIH comparado con no usarlo. Dos estudios han mostrado que los usuarios de preservativos tienen un mayor número de parejas sexuales que los varones que no lo usan. Sin embargo, este factor no se consideró en el análisis de ajuste por los factores de confusión56,57. Teniendo en cuenta que esta confusión residual podría haber reforzado la asociación de haberse ajustado, se podría considerar aumentar la calidad de la evidencia.
6.2.6. Clasificación global de la calidad de la evidencia
La clasificación global de la calidad de la evidencia implica realizar un juicio general de la calidad entre los desenlaces clave para una determinada pregunta clínica14. Aunque GRADE propone un proceso estructurado para valorar cinco factores que permiten bajar la calidad de la evidencia, seguido de tres factores que permiten aumentarla cuando se parte de estudios observacionales, la clasificación de la calidad de la evidencia no debe entenderse como un proceso binario; corresponde más bien a un juicio ponderado en un espectro continuo determinado por la confianza en los estimadores del efecto para apoyar una recomendación.
En el proceso de evaluación de la calidad de la evidencia normalmente se consideran varios desenlaces de interés clave para la toma de decisiones que pueden tener diferentes grados de calidad de la evidencia. Para la determinación global de la calidad de la evidencia es necesario proceder como sigue:
- Considerar solo los desenlaces clave para la toma de decisiones.
- Si la calidad de la evidencia es la misma para todos los desenlaces clave, se toma esta calidad como la calidad global de la evidencia para apoyar la recomendación.
- Si la calidad de la evidencia varía entre los desenlaces de interés clave, se toma la calidad más baja entre estos desenlaces como la calidad global de la evidencia para apoyar la recomendación.
Por otro lado, GRADE contempla dos situaciones en las que se puede considerar un cambio en la importancia de los desenlaces de interés y, por tanto, puede variar el juicio sobre la calidad global de la evidencia:
- Un desenlace de interés resulta no ser clave a la luz de los resultados de la literatura. Por ejemplo, un grupo de trabajo puede considerar que las náuseas y vómitos son un desenlace clave para apoyar una recomendación sobre un determinado tratamiento; si la literatura muestra que este desenlace tiene una incidencia muy baja, puede pasar a considerarse importante en lugar de clave.
- Un desenlace de interés resulta no ser clave si los estimadores del efecto disponibles no modificaran una recomendación o su fuerza al compararlos con los estimadores de otros desenlaces de interés clave en la misma recomendación. Una revisión sobre el uso de estatinas en pacientes sin enfermedad coronaria pero con alto riesgo estableció como desenlaces clave la mortalidad cardiovascular, el infarto de miocardio, el ictus y los efectos adversos58. Los resultados mostraron una reducción importante de infartos e ictus, aunque la reducción en la mortalidad no fue significativa. Los efectos adversos fueron poco frecuentes y eran reversibles con la interrupción del tratamiento. Mientras que la calidad de la evidencia para infartos, ictus y efectos adversos fue alta, para mortalidad fue moderada por imprecisión. Considerando el conjunto de desenlaces de interés para esta pregunta clínica y los resultados consistentes favorables al tratamiento, la calidad global de la evidencia podría clasificarse como alta.
6.3. Presentación de los resultados de la evaluación de la evidencia: elaboración de perfiles de evidencia GRADE
Los perfiles de evidencia son un buen método para presentar de forma resumida la evidencia disponible, los juicios sobre su calidad y los efectos de diferentes estrategias o intervenciones para cada uno de los desenlaces de interés. Los usuarios de la literatura científica (clínicos, pacientes, público general, desarrolladores de guías y responsables de tomar de decisiones) tienen necesidades específicas en cuanto al contenido y detalle de los resúmenes de la evidencia y por ello existen diferentes formatos de presentación que van destinados a públicos diferentes13.
Se dispone principalmente de dos formatos de presentación de los resúmenes de la evidencia:
Los perfiles de evidencia GRADE (GRADE evidence profile) (ver anexo 6.4) incluyen un juicio explícito de cada factor que determina la calidad de la evidencia para cada desenlace de interés, así como un resumen de los resultados para cada uno de los desenlaces de interés. Estas tablas están destinadas a autores de revisiones y elaboradores de tablas de resumen de la evidencia, y aseguran que los juicios se han valorado de forma sistemática y transparente. Además, permiten a terceras personas revisar y evaluar los juicios realizados en el proceso de clasificación de calidad de la evidencia.
Los grupos de trabajo en las guías de práctica clínica deben utilizar los perfiles de evidencia para asegurar que los juicios en los que se basa la evaluación de la calidad de la evidencia se reflejan de manera explícita. En la figura 6.5 se muestra un ejemplo de perfil de evidencia GRADE.
El programa de distribución libre GRADEPro ofrece la posibilidad de realizar dos formatos de perfil de evidencia: un perfil de evidencia clásico (GRADE evidence profile) y un perfil GRADE utilizado por la American College of Chest Physicians (GRADE profile (ACCP)). En esta sección se describe el segundo por ser el más detallado y explícito.
Las tablas de resumen de resultados (Summary of Findings table) presentan la misma información que los perfiles de evidencia de forma más sintética, omitiendo los detalles sobre la evaluación de la calidad. Son más útiles para revisiones sistemáticas y van destinadas a una audiencia más amplia, que incluye a los usuarios finales de síntesis de evidencia.
Ambas tablas muestran la confianza en los estimadores del efecto (calidad de la evidencia) y su magnitud tanto en términos relativos como absolutos, que pueden expresarse en función de diferentes riesgos basales. El proceso de elaboración de los dos tipos de tabla y la información necesaria para crearlas son los mismos. GRADEPro, incorporado en la herramienta Guideline Development Tool (http://www.guidelinedevelopment.org/), facilita la elaboración de ambos tipos de tablas, permitiendo importar los resultados numéricos desde un archivo RevMan.
Un aspecto fundamental tanto del perfil de evidencia como de la tabla resumen de resultados son las notas a pie de tabla. Las notas se utilizan para razonar y justificarlos juicios sobre la calidad de la evidencia y otras decisiones que el grupo de trabajo toma en el proceso de síntesis de la literatura y evaluación de la calidad de la evidencia. Es importante que la redacción de estas notas se realice de forma homogénea y concisa, aportando la información imprescindible que permita al usuario entender los juicios realizados. Ver en el anexo 6.5 más detalles sobre la elaboración de perfiles de evidencia GRADE.
6.4. Redacción de la evidencia para la pregunta clínica
Cada pregunta clínica debe acompañarse de un resumen estructurado de la literatura científica identificada y valorada para apoyar las recomendaciones. Para presentar el resumen de la literatura de forma narrativa, se describirán brevemente los resultados de la búsqueda bibliográfica realizada, así como el proceso de selección de los estudios valorados para apoyar las recomendaciones.
Posteriormente, debe desarrollarse un breve resumen de los estudios valorados, describiendo su diseño, características principales y los estimadores del efecto para cada desenlace de interés. Debe señalarse el número de estudios que informan sobre el desenlace de interés, el número de eventos en caso de desenlaces dicotómicos o el número de participantes en caso de desenlaces continuos, y el estimador del efecto en términos relativos con su intervalo de confianza. Los estimadores del efecto para expresar desenlaces dicotómicos son el riesgo relativo (RR), odds ratio (OR) o la diferencia de riesgo, aunque existen otras, como hazard ratio (HR). Por otro lado, la reducción relativa del riesgo (RRR) es una buena medida del efecto para expresar en términos porcentuales el riesgo relativo59.Tanto RR como OR y RRR son medidas robustas, puesto que son constantes entre los diferentes grupos de riesgo basal.
La presentación de resultados en términos de probabilidades o porcentajes puede plantear alguna dificultad, sobre todo cuando deben interpretarse eventos raros o cuando quieren trasladarse los resultados de la investigación a la toma de decisiones59-61. En cambio, las frecuencias naturales para expresar diferencias en términos absolutos son más inteligibles para interpretar diferencias por parte de los usuarios de la literatura científica62,63. En caso de expresar la diferencia de riesgos en términos absolutos de la intervención evaluada, es preferible proceder de la siguiente forma:
- Hacerlo cuando exista un efecto significativo.
- Expresarla en frecuencias naturales (por ejemplo, número de pacientes mostrando un desenlace por cada 100 o 1000 pacientes tratados).
- Describir el valor del riesgo basal (o del grupo control) a partir del cual se ha calculado la diferencia de riesgos.
- En caso de existir diferentes grupos de riesgo, describir la diferencia para cada uno de estos grupos.
Existen múltiples maneras de redactar los resultados de la literatura que apoyan las recomendaciones siguiendo estas indicaciones. Un ejemplo en una revisión sistemática sobre la eficacia y la seguridad de la termoplastia bronquial en los adultos con asma22 describía de este modo los resultados para uno de los desenlaces de interés: “Los pacientes que recibieron termoplastia tuvieron un mayor riesgo de hospitalización por eventos adversos respiratorios durante el periodo de tratamiento (tres ensayos, 429 participantes; RR 3,50; IC del 95%: 1,26 a 9,68; calidad de la evidencia alta), lo que representa un aumento absoluto de entre el 2% y el 8% durante el periodo de tratamiento. Esto significa que seis de cada 100 pacientes tratados con termoplastia (IC del 95%: 1 a 21) requerirían una hospitalización durante el periodo de tratamiento”.
Finalmente, se debe informar de la calidad de la evidencia para cada uno de los desenlaces evaluados, así como de la principal razón que haya suscitado una posible reducción de la misma. Un buen lugar para indicar la calidad de la evidencia es al final del párrafo en el que se describe la magnitud del efecto para cada desenlace, o de forma adyacente al texto en el que se realiza la descripción narrativa (figura 6.6).

Fuente: Guía de práctica clínica de atención al embarazo y puerperio. Ministerio de Sanidad, Servicios Sociales e Igualdad. Agencia de Evaluación de Tecnologías Sanitarias de Andalucía; 2014. Guías de Práctica Clínica del SNS: AETSA 2011/10.
Los apartados descritos se complementan con la inclusión de anexos electrónicos que recojan las tablas de resumen de los hallazgos (SoF) o los perfiles de evidencia para cada una de las preguntas clínicas. Estos anexos pueden complementarse con la inclusión, también en forma electrónica, de cualquier análisis complementario que haya realizado el grupo de trabajo, o de tablas descriptivas de las características de los estudios incluidos (ver capítulo 12,“Edición de las Guías de Práctica Clínica”).
6.5. Evaluación de la calidad de la evidencia en preguntas de tipo diagnóstico
Las recomendaciones sobre pruebas diagnósticas comparten el fundamento lógico de las recomendaciones para intervenciones terapéuticas. Sin embargo, para responder a una pregunta relacionada con una prueba diagnóstica, hay que tener en cuenta los siguientes aspectos:
- Mientras algunas pruebas aportan resultados positivos y negativos, otras proporcionan resultados ordinales o continuos. Para simplificar la discusión, GRADE asume un abordaje diagnóstico que categoriza los resultados del test como positivos o negativos, lo que finalmente lleva a la decisión de tratar o no tratar.
- En la práctica clínica habitual, a menudo se realiza una estrategia diagnóstica (conjunto de pruebas) y no una única prueba.
- Las pruebas comúnmente llamadas diagnósticas se pueden utilizar para diferentes fines; por ejemplo, la identificación de desequilibrios fisiológicos, el establecimiento de un pronóstico, la monitorización de una enfermedad o la respuesta a un tratamiento, o para realizar un cribado o el diagnóstico de una enfermedad. Por ello, los paneles de guías deberían definir de forma explícita cuál es el objetivo del test.
- La finalidad de una prueba o estrategia diagnóstica puede ser la sustitución (de una prueba existente más invasiva, con mayor coste o con menor precisión), la clasificación o triaje (para seleccionar los casos que recibirán más pruebas) o como prueba adicional (a una prueba diagnóstica).
Los grupos elaboradores de guías deben definir de forma explícita estos aspectos durante la elaboración de las preguntas. Para simplificar la explicación en los apartados sobre diagnóstico, se ha partido de aquellas pruebas con un resultado categórico (como positivo o negativo), aunque en principio el mismo razonamiento se debe aplicar a pruebas que proporcionan resultados ordinales o continuos.
6.5.1 Valoración de la calidad de la evidencia para preguntas de tipo diagnóstico
GRADE considera que el mejor diseño de estudio que puede demostrar la utilidad de una prueba diagnóstica es un ensayo clínico (test-treat RCT) que distribuya de forma aleatoria los pacientes entre el grupo experimental (al que se aplica la prueba diagnóstica a estudio) y el grupo control (al que se le aplica la prueba estándar), y que mida el efecto sobre los desenlaces clínicos que son importantes para el paciente. Cuando se cuenta con este tipo de estudios, GRADE indica que se aplique el marco para preguntas de tipo intervención4.
Sin embargo, en la mayoría de los casos solo se dispone de estudios que miden la precisión diagnóstica de la prueba. Con estos estudios, el grupo elaborador deberá realizar inferencias sobre las consecuencias clínicas de obtener un determinado resultado de la prueba.
De manera similar al marco GRADE para preguntas de tipo intervención, cuando se dispone de estudios de pacientes consecutivos en los que se comparan los resultados de la prueba a estudio con los de la prueba estándar de referencia, se parte de evidencia de calidad alta, que puede disminuir. Los otros diseños de estudios de precisión diagnóstica aportan evidencia de calidad baja.
La valoración de la calidad de la evidencia se realiza para cada uno de los desenlaces de interés. Para los estudios de pruebas diagnósticas con un resultado categórico (positivo o negativo) deben considerarse los desenlaces que dependen de la sensibilidad (verdaderos positivos y falsos negativos), así como los que dependen de la especificidad (verdaderos negativos y los falsos positivos).
En referencia al riesgo de sesgos de los estudios, se deben tener en cuenta los aspectos que definen la calidad de un buen estudio de precisión diagnóstica, como la representatividad de la población del estudio, o que tanto la prueba a estudio como la de referencia se hayan aplicado al conjunto de los pacientes del estudio. Para ello GRADE sugiere la utilización de los criterios de la herramienta QUADAS (anexo 6.6) para valorar el riesgo de sesgo de los estudios y entre ellos64. La existencia de limitaciones serias en los estudios indicaría un posible riesgo de sesgos que posiblemente lleven a disminuir la calidad de la evidencia en uno o dos niveles (por ejemplo, el sesgo de incluir únicamente a varones en el estudio), que habría que valorarlo como tal (salvo por causa justificada, en caso de proceso patológico o asistencial en que solo estuvieran afectados varones). Hasta 1999 la FDA no dispuso la necesidad de incluir mujeres y hombres en los ensayos clínicos para considerar de calidad el ensayo.
En los estudios de evaluación de pruebas diagnósticas se establece un criterio, prueba o estrategia diagnóstica (patrón oro) que permite identificar de la forma más aproximada qué pacientes tienen realmente la enfermedad. Dado que la prueba de referencia puede cambiar a lo largo del tiempo, debe considerarse aquella más aceptada en la actualidad.
En cuanto a la valoración del carácter indirecto de la evidencia, su valoración en este caso presenta dificultades adicionales en comparación a las preguntas de intervención terapéutica. En primer lugar, se debe valorar cuál es la población, el escenario, la intervención (la prueba en estudio) y el comparador (otra prueba en estudio o el estándar de referencia). Si la pregunta clínica trata sobre la opción entre dos pruebas, ninguna de las cuales es el estándar de referencia, se debe valorar si ambas se han comparado de forma directa y con el test de referencia en el mismo estudio o en estudios separados.
En estas situaciones es más frecuente que exista evidencia indirecta, por lo que el grupo elaborador deberá realizar inferencias sobre las consecuencias clínicas de obtener un determinado resultado de la prueba.
A grandes rasgos, la clasificación correcta de los pacientes se asocia con beneficios o con una reducción de efectos adversos, mientras que la clasificación incorrecta se asocia con efectos adversos. Lo que el grupo elaborador de guías debe valorar es si los beneficios de la correcta clasificación de parte de los pacientes puede tener un mayor impacto que los daños potenciales derivados de la clasificación incorrecta del resto6. Por ejemplo, si se considera la sustitución de la prueba de provocación por inhalación por una prueba cutánea para el diagnóstico de asma laboral en pacientes con sospecha de asma por exposición a moléculas de alto peso molecular en el trabajo, las consecuencias de clasificar un paciente como falso positivo llevarían al cese innecesario de su puesto de trabajo, la utilización de equipos de protección personal o de métodos para eliminar o disminuir la concentración de alérgenos de forma innecesaria. Por otro lado, las consecuencias de clasificarlo como un falso negativo supondrían un retraso en el diagnóstico de la enfermedad, una exposición prolongada y el posible deterioro por la enfermedad. En este último caso, la calidad de la evidencia disminuiría un nivel por las dudas existentes en relación a las consecuencias para el paciente de ser clasificado como falso positivo4.
Para poder decir que una prueba o estrategia diagnóstica tiene un impacto sobre los desenlaces importantes para los pacientes suele ser necesario que exista evidencia de calidad sobre los efectos del manejo posterior. Sin embargo, aunque no haya un tratamiento efectivo disponible, utilizar una prueba precisa puede ser beneficioso si reduce los efectos adversos, el coste o la ansiedad, al descartar un diagnóstico ominoso o sise mejora el bienestar del paciente por la información que se le puede proporcionar sobre su pronóstico al confirmar el diagnóstico. De todos modos, antes de realizar este tipo de inferencias, hay que contar con dicha información y que esta sea fiable.
En principio, el resto de criterios (inconsistencia, imprecisión y sesgo de publicación), se consideran de forma similar al caso de preguntas de tipo intervención4, aunque los métodos para determinar si se cumplen estos criterios están peor establecidos, con dificultades a la hora de valorar el criterio de la imprecisión o el del sesgo de publicación18 (ver anexo 6.7, “Tablas de evidencia GRADE para preguntas de tipo diagnóstico”).
6.6. Evaluación de la calidad de la evidencia en preguntas sobre pronóstico
El pronóstico refleja la probabilidad de que tenga lugar un desenlace en personas con una enfermedad o condición concreta o con una característica particular (edad, sexo o perfil genético). Los estudios de este tipo pueden tener diferentes objetivos:
- Conocer el pronóstico de un paciente representativo de una población general definida.
- Establecer el impacto de las características de los pacientes sobre el riesgo de un determinado evento (factores pronósticos).
- Estimar el riesgo individual de un paciente mediante reglas de predicción clínica.
El primer artículo publicado por el grupo GRADE sobre el abordaje de estudios de tipo pronóstico propone la forma de valorar la confianza en la evidencia disponible para preguntas sobre el pronóstico de un paciente representativo de una población general definida (por ejemplo, cuando se quiere conocer el riesgo basal de la población para estimar el efecto absoluto de una intervención)19. Es importante señalar que las indicaciones descritas en el artículo van dirigidas a los elaboradores de revisiones sistemáticas que ofrezcan información para guiar la formulación de recomendaciones sobre este aspecto.
Los criterios propuestos para clasificar la calidad de la evidencia en las preguntas clínicas de pronóstico son los mismos que para el resto de preguntas, aunque se tienen en cuenta las diferencias debidas al tipo de estudios adecuados para responder este tipo de preguntas.
6.6.1. Consideraciones sobre el diseño de estudio
A diferencia de lo que ocurre con los estudios de intervención, en pronóstico los estudios longitudinales de cohortes parten de una confianza alta. GRADE señala que la evidencia de tipo pronóstico puede originarse tanto a partir de estudios observacionales como a partir de brazos individuales de ensayos clínicos, que podrían interpretarse como estudios observacionales independientes (cada brazo supondría un estudio observacional). Cuando no se realiza ninguna comparación, es decir, cuando lo que interesa es conocer la tasa de eventos en cada brazo del estudio, la distinción entre ensayos y cohortes deja de ser relevante.
Sin embargo, la confianza en los estimadores de pronóstico obtenidos de estudios observacionales será mayor que la confianza en los obtenidos a partir de ensayos clínicos aleatorizados, puesto que los ensayos suelen excluir pacientes relevantes para la pregunta sobre el pronóstico general (pacientes con comorbilidad, de determinadas edades, etc.). Una excepción la constituyen los ensayos pragmáticos grandes, con criterios de inclusión amplios, que incluyen pacientes de la población típica y ofrecen, por tanto, estimadores con un nivel de confianza mayor.
Por ejemplo, en una revisión sistemática sobre la frecuencia de complicaciones de sangrado en pacientes tratados con antagonistas de la vitamina K, los autores encontraron que los estimadores del riesgo obtenidos en ensayos de pequeño y mediano tamaño eran menores (1,8; rango intercuartílico (RIC) de 1,36 a 2,50 por paciente y año) que los estimadores en estudios observacionales grandes (mediana de 2,68; RIC de 1,75 a 4,40) y en ensayos pragmáticos grandes (3,09; RIC de 2,20 a 3,36), siendo similares los resultados de los ensayos pragmáticos y los estudios observacionales65.
6.6.2. Factores que permiten bajar la calidad de la evidencia
6.6.2.1. Limitaciones en el diseño o ejecución de los estudios
A la hora de evaluar el riesgo de sesgo de los estudios de tipo pronóstico se pueden utilizar instrumentos como el Quality in Prognosis Study (QUIPS)66, una versión modificada de la escala de Newcastle-Ottawa67 o la propuesta ACROBAT-NRSI comentada en la sección 6.2.4.1. de este capítulo. No obstante, el grupo GRADE propone usar unos criterios a partir del “Users’ Guides to the Medical Literature” de JAMA68, como la definición y representatividad de la población, el cumplimiento del seguimiento y la medida objetiva del resultado. Estos criterios se resumen en la figura 6.7.

Si la evaluación del riesgo de sesgo muestra mucha variabilidad entre los estudios disponibles, se sugiere realizar un análisis de sensibilidad. Si el análisis sugiere diferencias en los estimadores entre estudios de mayor y menor riesgo de sesgo, se sugiere utilizar los estimadores de los estudios de menor riesgo de sesgo sin necesidad de disminuir la confianza en los estimadores.
6.6.2.2. Inconsistencia entre los resultados de diferentes estudios
Este factor se valora de forma similar a las preguntas de intervención. Esto incluye la variabilidad en los estimadores de resultado disponibles, el grado de solapamiento de sus intervalos de confianza y su situación en relación a los umbrales relevantes para la toma de decisiones. Por ejemplo, Lopes65 observó que, en pacientes que utilizaban antagonistas de la vitamina K, la variación en los estimadores de sangrado entre los estudios era de hasta 10 veces mayor, llevando a un I2 de más del 90%. La tasa absoluta variaba entre 0,65 y 7,53 por 100 pacientes y año, una variación que conllevaría a tomar decisiones alternativas sobre el manejo de los pacientes. En este caso, la calidad de la evidencia debería bajarse por inconsistencia.
El grupo GRADE señala que en el contexto de los estudios de tipo pronóstico, el estadístico I2 presenta limitaciones y no es un buen indicador de heterogeneidad. Los estudios de tipo pronóstico suelen tener tamaños de muestra grandes que resultan en intervalos de confianza individuales muy estrechos. Esto hace que el I2 del estimador global sea extremadamente alto, incluso en el caso de existir poca inconsistencia entre los estudios. Por ello se sugiere que, para juzgar la presencia de inconsistencia, se evalúe la variación de los estimadores puntuales y no se valore el estadístico I2.
También se señala que debe anticiparse la presencia de inconsistencia sustancial en los resultados y por lo tanto deberían generarse hipótesis a priori que pudieran explicar la heterogeneidad encontrada. Si los análisis de subgrupos demuestran diferencias entre las diferentes categorías (por ejemplo, entre pacientes mayores o jóvenes, o más enfermos o menos enfermos) y cumplen con los criterios de credibilidad antes expuestos, el problema de la inconsistencia podría resolverse generando estimadores separados para los subgrupos relevantes.
El tamaño de la muestra puede ser otra fuente de heterogeneidad. En primer lugar, los estudios con un tamaño de muestra pequeño están más sujetos al sesgo de publicación. En segundo lugar, un tamaño de muestra pequeño puede suponer una dificultad para detectar deficiencias metodológicas que aumenten el sesgo. Estas consideraciones sugieren que una buena opción puede ser excluir los estudios pequeños cuando existan diferencias en los resultados entre los estudios grandes y los pequeños.
6.6.2.3. Disponibilidad de evidencia indirecta
Debe considerarse si la población estudiada en los estudios disponibles corresponde a la población de interés para apoyar la recomendación, y si los desenlaces medidos representan a los escogidos como clave. Por ejemplo, los resultados de una revisión sistemática sobre la frecuencia de suicidio en pacientes con trastornos alimenticios69, en la que la mayoría de las pacientes presentan trastornos alimenticios complicados, no serían aplicables a pacientes con trastornos alimenticios no complicados.
6.6.2.4. Imprecisión de los estimadores delefecto
Los juicios sobre la imprecisión de los estimadores de riesgo se basan en la amplitud del intervalo de confianza alrededor del estimador y en su situación en relación al umbral relevante para la toma de decisiones clínicas. Se propone que, para los estudios de tipo pronóstico, disminuya la confianza en el estimador si el efecto sobre el paciente o sobre la decisión clínica fuera diferente en función de que el verdadero estimador se situara en el límite superior o inferior del intervalo de confianza.
Esto se ilustra con una propuesta sobre una decisión en el marco de un programa de cáncer que quiere ofrecer un seguimiento intensivo para los pacientes que tengan un riesgo de desarrollar cáncer mayor de 10 por 1000. Se consideran los resultados de una revisión sistemática que valora el riesgo de desarrollar cáncer de esófago en pacientes con esófago de Barret (una displasia precursora de cáncer esofágico)70. La estimación del riesgo es de 10,2 (IC95% de 6,3 a 16,4) por 1000 pacientes y año, calculado en base a la observación de 31 casos en 3445 pacientes y año. Si el límite inferior del intervalo representara la realidad (6,3 por 1000 pacientes y año), no realizaríamos el seguimiento intensivo; pero si fuera el límite superior el que representara la realidad (16,4 por 1000 pacientes y año), entonces sí lo realizaríamos. Así, en esta situación se disminuiría la confianza en el estimador del riesgo por imprecisión.
6.6.2.5. Sesgo de publicación
Los test estadísticos más comunes para valorar el sesgo de publicación (por ejemplo, test de Egger) se pueden aplicar cuando la heterogeneidad es baja y los datos se distribuyen normalmente. Como las proporciones de los estudios observacionales normalmente tienen una distribución asimétrica y la inconsistencia de los resultados suele ser alta, el uso de estos instrumentos no es apropiado. Como alternativa, el grupo GRADE señala que las pruebas basadas en rangos (por ejemplo, la prueba de Begg) pueden ser de utilidad para valorar el sesgo de publicación.
6.6.3. Factores que permiten aumentar la calidad de la evidencia
Para preguntas de tipo pronóstico se proponen dos aspectos para aumentar la confianza en los estimadores del efecto: la demostración de una magnitud del efecto importante o la identificación de un patrón en la acumulación de los eventos de interés en un periodo de tiempo determinado. Si bien se propone una situación específica en la que es posible aumentar la calidad de la evidencia cuando se utilizan estudios observacionales para responder preguntas terapéuticas (ver apartado 6.2.5), estas directrices no son tan claras en el contexto del análisis de estudios para responder a preguntas de tipo pronóstico19.
6.6.3.1. Magnitud del estimador del riesgo importante
Para ilustrar una situación en la que se podría aumentar la calidad de la evidencia por este aspecto, se pone como ejemplo el riesgo de desarrollar inhibidores para el factor terapéutico VIII utilizado en la prevención de hemorragias en la hemofilia leve. Los datos de un registro internacional indicaron que, en pacientes con mutaciones específicas, el riesgo de desarrollar estos inhibidores puede ser mayor del 30%, siendo el límite inferior del intervalo del 20%71. Si se asume que la mayoría de los pacientes con un riesgo mayor al 5% modificarían su decisión para escoger un tratamiento alternativo a pesar de tener una menor eficacia y mayores efectos adversos, la confianza en el estimador obtenido de la literatura aumentaría.
6.6.3.2. Identificación de un patrón en la acumulación de los eventos de interés en un periodo de tiempo determinado
La situación análoga al gradiente dosis-respuesta aplicada a preguntas de intervención se puede plantear a preguntas de tipo pronóstico, si se identifica una acumulación consistente del número de eventos de interés a lo largo del tiempo siguiendo un patrón determinado (tendencia lineal o de otro tipo) que permita cuantificar un riesgo determinado para un paciente.
Por ejemplo, en una revisión sistemática se realizó un metanálisis y una metarregresión para estimar el riesgo acumulado de recurrencia de ictus72. Se obtuvieron estimadores acumulados para diferentes momentos en el tiempo sobre el riesgo de recurrencia tras el primer ictus (30 días, 1 año, 5 y 10 años). El metanálisis y la metarregresión permitieron identificar una tendencia temporal con respecto al riesgo de recurrencia pese a la variabilidad de las estimaciones de los diferentes estudios primarios.
En el supuesto de querer obtener una estimación del riesgo de recurrencia de ictus a los dos años para apoyar una recomendación, se podrían seleccionar los resultados de un estudio representativo del riesgo basal de la población sobre la que se formulará la recomendación. Si el estimador del riesgo a los dos años en este estudio se aproximara al proporcionado por el metanálisis y la metarregresión, la confianza en este aumentará.
6.7. Calidad de los resultados de síntesis de evidencia cualitativa
En el contexto de la síntesis de evidencia cualitativa, se entiende por calidad de la evidencia la valoración de hasta qué punto el hallazgo de la revisión es una representación razonable del fenómeno de interés (es decir, es improbable que el fenómeno de interés sea esencialmente diferente al hallazgo de la investigación).El grupo GRADE ha desarrollado una propuesta denominada CerQUAL con el objetivo de definir un marco que permita valorar la confianza en los hallazgos en revisiones de estudios cualitativos73,74. Esta propuesta contiene cuatro factores.

Inicialmente, se debe valorar tanto la calidad metodológica de los estudios individuales que contribuyen a cada hallazgo, para lo que se propone la adaptación de la herramienta de lectura crítica CASP para estudios cualitativos (ver figura 6.8), así como la coherencia de cada uno de los hallazgos. Así, se podría considerar la valoración de la calidad metodológica como el análogo del riesgo de sesgo y la coherencia como el correspondiente al de inconsistencia.

Otro factor que debe considerarse es la relevancia de cada estudio individual que contribuye al hallazgo de la revisión para la pregunta de investigación (hasta qué punto la evidencia que apoya un hallazgo es aplicable al contexto específico de la pregunta). Finalmente, es necesario considerar la suficiencia de los datos que contribuyen al hallazgo. Estos dos criterios serían, respectivamente, los análogos del carácter indirecto de la evidencia y de la imprecisión del sistema GRADE. En el caso de sesgo de publicación, el grupo todavía no ha establecido si se debe aplicar o no este criterio a la síntesis de evidencia cualitativa.
CerQUAL considera las siguientes cuatro categorías para la calidad de la evidencia:
- Calidad alta: es altamente probable que el hallazgo de la revisión sea una representación razonable del fenómeno de interés.
- Calidad moderada: es probable que el hallazgo de la revisión sea una representación razonable del fenómeno de interés.
- Calidad baja: es posible que el hallazgo de la revisión sea una representación razonable del fenómeno de interés.
- Calidad muy baja: no está claro si el hallazgo de la revisión es una representación razonable del fenómeno de interés.
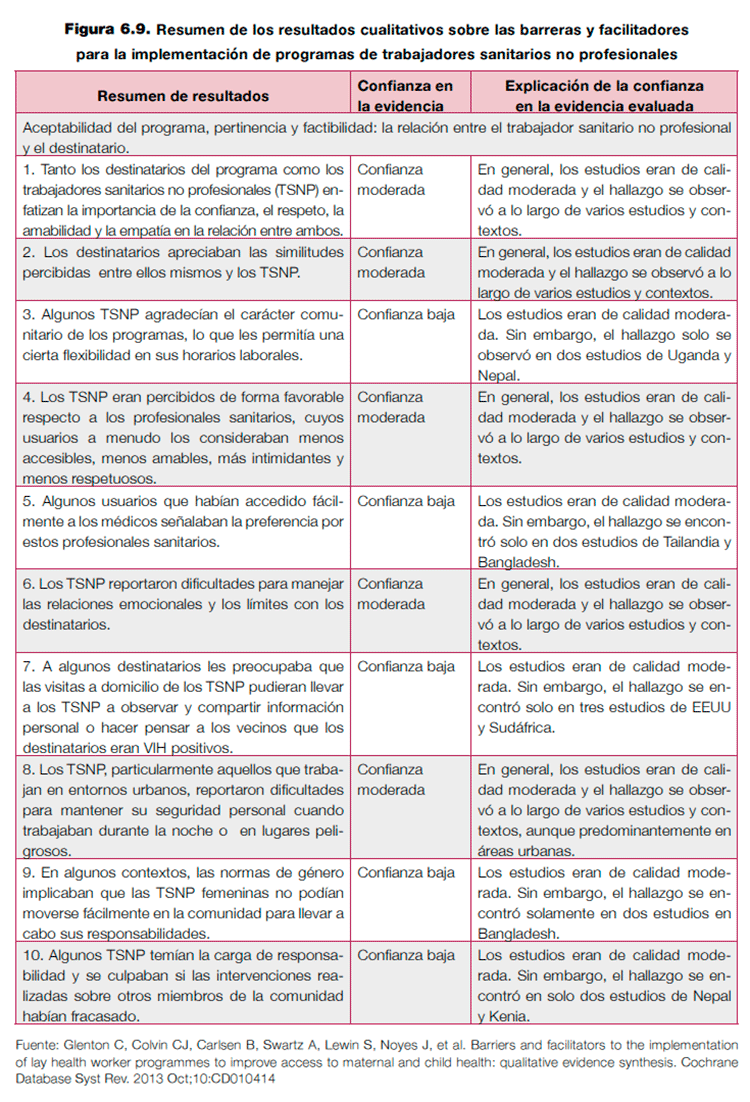
Existe un ejemplo de la utilización de esta propuesta en una revisión Cochrane que aborda las barreras y facilitadores para la implementación de programas de trabajadores sanitarios no profesionales para mejorar el acceso a la salud maternoinfantil75. CERQUAL propone presentar unas tablas de resumen en las que se describe la calidad de la evidencia para cada uno de los hallazgos en filas sucesivas. En la figura 6.9 se muestra un ejemplo comentado de una revisión Cochrane.
Resumen de los Aspectos Clave
Bibliografía 6. Evaluación y síntesis de la evidencia científica
1. Alonso-Coello P, Rigau D, Solà I, Martínez García L. La formulación de recomendaciones en salud: el sistema GRADE. Med Clin (Barc). 2013 Apr;140(8):366-73.
2. Schünemann H, Brozek J, Guyatt G, Oxman A, editores. GRADE handbook for grading quality of evidence and strength of recommendations. The GRADE Working Group, 2013.
3. Schünemann HJ, Oxman AD, Brozek J, Glasziou P, Jaeschke R, Vist GE, et al. Grading quality of evidence and strength of recommendations for diagnostic tests and strategies. BMJ [Internet]. 2008 May;336(7653):1106-10 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2386626/.
4. Brozek JL, Akl EA, Jaeschke R, Lang DM, Bossuyt P, Glasziou P, et al. Grading quality of evidence and strength of recommendations in clinical practice guidelines: Part 2 of 3. The GRADE approach to grading quality of evidence about diagnostic tests and strategies.Allergy. 2009 Aug;64(8):1109-16.
5. Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, et al. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. J Clin Epidemiol. 2011 Apr;64(4):383-94.
6. Hsu J, Brozek JL, Terracciano L, Kreis J, Compalati E, Stein AT, et al. Application of GRADE: making evidence-based recommendations about diagnostic tests in clinical practice guidelines. Implement Sci [Internet]. 2011 Jun;6:62 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3126717/.
7. Guyatt GH, Oxman AD, Vist G, Kunz R, Brozek J, Alonso-Coello P, et al. GRADE guidelines: 4. Rating the quality of evidence--study limitations (risk of bias). J Clin Epidemiol. 2011 Apr;64(4):407-15.
8. Guyatt GH, Oxman AD, Kunz R, Woodcock J, Brozek J, Helfand M, et al. GRADE guidelines: 7. Rating the quality of evidence--inconsistency. J Clin Epidemiol. 2011 Dec;64(12):1294-302.
9. Guyatt GH, Oxman AD, Kunz R, Woodcock J, Brozek J, Helfand M, et al. GRADE guidelines: 8. Rating the quality of evidence--indirectness. J Clin Epidemiol. 2011 Dec;64(12):1303-10.
10. Guyatt GH, Oxman AD, Kunz R, Brozek J, Alonso-Coello P, Rind D, et al. GRADE guidelines 6. Rating the quality of evidence--imprecision. J Clin Epidemiol. 2011 Dec;64(12):1283-93.
11. Guyatt GH, Oxman AD, Montori V, Vist G, Kunz R, Brozek J, et al. GRADE guidelines: 5. Rating the quality of evidence--publication bias. J Clin Epidemiol. 2011 Dec;64(12):1277-82.
12. Guyatt GH, Oxman AD, Sultan S, Glasziou P, Akl EA, Alonso-Coello P, et al. GRADE guidelines: 9. Rating up the quality of evidence. J Clin Epidemiol. 2011 Dec;64(12):1311-6.
13. Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, et al. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. J Clin Epidemiol. 2011 Apr;64(4):383-94.
14. Guyatt G, Oxman AD, Sultan S, Brozek J, Glasziou P, Alonso-Coello P, et al. GRADE guidelines: 11. Making an overall rating of confidence in effect estimates for a single outcome and for all outcomes. J Clin Epidemiol. 2013 Feb;66(2):151-7.
15. Guyatt GH, Oxman AD, Santesso N, Helfand M, Vist G, Kunz R, et al. GRADE guidelines: 12. Preparing summary of findings tables-binary outcomes. J Clin Epidemiol. 2013 Feb;66(2): 158-72.
16. Guyatt GH, Thorlund K, Oxman AD, Walter SD, Patrick D, Furukawa TA, et al. GRADE guidelines: 13. Preparing summary of findings tables and evidence profiles-continuous outcomes. J Clin Epidemiol. 2013 Feb;66(2):173-83.
17. Balshem H, Helfand M, Schünemann HJ, Oxman AD, Kunz R, Brozek J, et al. GRADE guidelines 3: rating the quality of evidence. J Clin Epidemiol. 2011 Apr;64(4):401-6.
18. Gopalakrishna G, Mustafa RA, Davenport C, Scholten RJ, Hyde C, Brozek J, et al. Applying Grading of Recommendations Assessment, Development and Evaluation (GRADE) to diagnostic tests was challenging but doable. J Clin Epidemiol [Internet]. 2014 Jul;67(7):760-8 [consultado 02/03/2016]. Disponible en: http://www.sciencedirect.com/science/article/pii/S0895435614000444.
19. Iorio A, Spencer FA, Falavigna M, Alba C, Lang E, Burnand B, et al. Use of GRADE for assessment of evidence about prognosis: rating confidence in estimates of event rates in broad categories of patients. BMJ [Internet]. 2015 Mar;350:h870 [consultado 02/03/2016]. Disponible en: http://www.bmj.com/content/350/bmj.h870.long.
20. Higgins JPT, Altman DG, Sterne JAC, editores. Chapter 8: Assessing risk of bias in included studies. En: Higgins JPT, Green S, editores. Cochrane Handbook for Systematic Reviews of Interventions [Internet].Version 5.1.0. London: The Cochrane Collaboration; 2011 [actualizado 03/2011; consultado 07/10/2014]. Disponible en: http://handbook.cochrane.org.
21. Hillmen P, Young NS, Schubert J, Brodsky RA, Socié G, Muus P et al. The complement inhibitor eculizumab in paroxysmal nocturnal hemoglobinuria. N Engl J Med [Internet].2006 Sep;355(12):1233-43 [consultado 02/03/2016]. Disponible en: http://www.nejm.org/doi/full/10.1056/NEJMoa061648#t=article.
22. Torrego A, Solà I, Munoz AM, RoquéiFiguls M, Yepes-Nuñez JJ, Alonso-Coello P, et al. Bronchial thermoplasty for moderate or severe persistent asthma in adults. Cochrane Database Syst Rev. 2014 Mar,3:CD009910.
23. Reeves BC, Deeks JJ, Higgins JPT, Wells GA. Chapter 13: Including non-randomized studies. En: Higgins JPT, Green S, editores. Cochrane Handbook for Systematic Reviews of Interventions [Internet]. Version 5.1.0. London: The Cochrane Collaboration; 2011 [actualizado 03/2011; consultado el 07/10/2015]. Disponible en: http://handbook.cochrane.org.
24. Deeks JJ, Dinnes J, D’Amico R, Sowden AJ, Sakarovitch C, Song F, et al. Evaluating nonrandomised intervention studies. Health Technol Assess 2003; 7(27): iii-x, 1-173.
25. Downs SH, Black N. The feasibility of creating a checklist for the assessment of the methodological quality both of randomised and non-randomised studies of health care interventions. J Epidemiol Community Health [Internet]. 1998 Jun;52(6):377-384 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1756728/.
26. MacLehose RR, Reeves BC, Harvey IM, Sheldon TA, Russell IT, Black AM. A systematic review of comparisons of effect sizes derived from randomised and non-randomised studies. Health Technol Assess [Internet]. 2000; 4(34):1-154.
27. Wells GA, Shea B, O’Connell D, Peterson J, Welch V, Losos M, et al. The Newcastle-Ottawa Scale (NOS) for assessing the quality of nonrandomised studies in meta-analyses [Internet]. [consultado 07/10/2014]. Disponible en: http://www.ohri.ca/programs/clinical_epidemiology/oxford.htm.
28. Sterne JAC, Higgins JPT, Reeves BC on behalf of the development group for ACROBAT-NRSI. A Cochrane Risk Of Bias Assessment Tool: for Non-Randomized Studies of Interventions (ACROBAT-NRSI). Version 1.0.0, 24 September 2014 [07/10/2014]. Disponible en: https://sites.google.com/site/riskofbiastool/.
29. Deeks JJ, Higgins JPT, Altman DG, editores. Chapter 9: Analysing data and undertaking metaanalyses. En: Higgins JPT, Green S, editores. Cochrane Handbook for Systematic Reviews of Interventions [Internet]. Version 5.1.0. London: The Cochrane Collaboration; 2011 [actualizado 03/2011; consultado 08/10/2014]. Disponible en: http://handbook.cochrane.org.
30. Alonso-Coello P, Zhou Q, Martinez-Zapata MJ, Mills E, Heels-Ansdell D, Johanson JF, et al. Meta-analysis of flavonoids for the treatment of haemorrhoids. Br J Surg. 2006 Aug;93(8):909-20.
31. Guyatt G, Wyer P, Ioannidis J. When to believe a subgroup analysis. En: Guyatt G, Rennie D, Meade MO, Cook DJ, editores. The users’ guides to the medical literature: a manual for evidence-based clinical practice. 2ª ed. New York: McGraw-Hill Medical; London: McGraw-Hill; 2008.
32. Sun X, Briel M, Walter SD, Guyatt GH. Is a subgroup effect believable? Updating criteria to evaluate the credibility of subgroup analyses. BMJ [Internet]. 2010 Mar;340:c117[consultado 02/03/2016]. Disponible en: http://www.bmj.com/content/340/bmj.c117.long.
33. Sun X, Ioannidis JP, Agoritsas T, Alba AC, Guyatt G. How to use a subgroup analysis: users’ guide to the medical literature. JAMA. 2014 Jan;311(4):405-11.
34. Sociedad Española de Anestesiología, Reanimación y Terapéutica del Dolor (SEDAR). Guía de práctica clínica para la optimización hemodinámica intraoperatoria de los pacientes adultos sometidos a cirugía no cardíaca. Manuscrito en prensa, 2015.
35. Gillies M, Palmateer N, Hutchinson S, Ahmed S, Taylor A, Goldberg D. The provision of nonneedle/syringe drug injecting paraphernalia in the primary prevention of HCV among IDU: asystematic review. BMC Public Health [Internet]. 2010 Nov;10:721 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3001732/.
36. Lim E, Ali Z, Ali A, Routledge T, Edmonds L, Altman DG, et al. Indirect comparison metaanalysis of aspirin therapy after coronary surgery. BMJ [Internet]. 2003 Dec;327(7427):1309 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC286307/.
37. Catalá-López F, Tobías A. Síntesis de la evidencia clínica y metanálisis en red con comparaciones indirectas. Med Clin (Barc). 2013 Feb;140(4):182-7.
38. Puhan MA, Schünemann HJ, Murad MH, Li T, Brignardello-Petersen R, Singh JA, et al. A GRADE Working Group approach for rating the quality of treatment effect estimates from network meta-analysis. BMJ. 2014 Sep;349:g5630.
39. Mills EJ, Ioannidis JP, Thorlund K, Schünemann HJ, Puhan MA, Guyatt GH. How to use an article reporting a multiple treatment comparison meta-analysis. JAMA. 2012 Sep;308(12): 1246-53.
40. Cipriani A, Furukawa TA, Salanti G, Geddes JR, Higgins JP, Churchill R, et al. Comparative efficacy and acceptability of 12 new-generation antidepressants: a multiple-treatments metaanalysis. Lancet. 2009 Feb 28;373(9665):746-58.
41. Pogue JM, Yusuf S. Cumulating evidence from randomized trials: utilizing sequential monitoring boundaries for cumulative meta-analysis. Control Clin Trials. 1997 Dec;18(6):580-93; discussion 661-6.
42. Quon BS, Gan WQ, Sin DD. Contemporary management of acute exacerbations of COPD: a systematic review and metaanalysis. Chest [Internet]. 2008 Mar;133(3):756-66 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pubmedhealth/PMH0026117/.
43. McGlothlin AE, Lewis RJ. Minimal clinically important difference: defining what really matters to patients. JAMA. 2014 Oct;312(13):1342-3.
44. Keurentjes JC, Van Tol FR, Fiocco M, Schoones JW, Nelissen RG. Minimal clinically important differences in health-related quality of life after total hip or knee replacement: A systematic review. Bone Joint Res [Internet]. 2012 May;1(5):71-7 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3626243/.
45. Luckett T, King M, Butow P, Friedlander M, Paris T. Assessing health-related quality of life in gynecologic oncology: a systematic review of questionnaires and their ability to detect clinically important differences and change. Int J Gynecol Cancer. 2010 May;20(4):664-84.
46. Martí-Carvajal AJ, Anand V, Cardona AF, Solà I. Eculizumab for treating patients with paroxysmal nocturnal hemoglobinuria. Cochrane Database Syst Rev. 2014 Oct;10:CD010340.
47. Cella D, Eton DT, Lai JS, Peterman AH, Merkel DE. Combining anchor and distribution-based methods to derive minimal clinically important differences on the Functional Assessment of Cancer Therapy (FACT) anemia and fatigue scales. J Pain Symptom Manage 2002 Dec;24(6):547-61.
48. Sterne JAC, Egger M, Moher D. editores. Chapter 10: Addressing reporting biases. En: Higgins JPT, Green S, editores. Cochrane Handbook for Systematic Reviews of Interventions [Internet]. Version 5.1.0. London: The Cochrane Collaboration; 2011 [actualizado 03/2011; consultado el 13/10/2014]. Disponible en: http://handbook.cochrane.org.
49. Cappelleri JC, Ioannidis JP, Schmid CH, de Ferranti SD, Aubert M, Chalmers TC, et al. Large trials vs meta-analysis of smaller trials: how do their results compare? JAMA. 1996 Oct;276(16):1332-8.
50. Sutton AJ, Duval SJ, Tweedie RL, Abrams KR, Jones DR. Empirical assessment of effect of publication bias on meta-analyses.BMJ [Internet]. 2000 Jun;320(7249):1574-7 .
51. Turner EH, Matthews AM, Linardatos E, Tell RA, Rosenthal R. Selective publication of antidepressant trials and its influence on apparent efficacy. N Engl J Med [Internet]. 2008 Jan;358(3):252-60 [consultado 02/03/2016]. Disponible en: http://www.nejm.org/doi/full/10.1056/NEJMsa065779#t=article.
52. Gilbert R, Salanti G, Harden M, See S. Infant sleeping position and the sudden infant death syndrome: systematic review of observational studies and historical review of recommendations from 1940 to 2002. Int J Epidemiol [Internet]. 2005 Aug;34(4):874-87 [consultado 02/03/2016]. Disponible en: http://ije.oxfordjournals.org/content/34/4/874.long.
53. Castellsagué X, Díaz M, Vaccarella S, de Sanjosé S, Muñoz N, Herrero R, et al. Intrauterine device use, cervical infection with human papillomavirus, and risk of cervical cancer: a pooled analysis of 26 epidemiological studies. Lancet Oncol. 2011 Oct;12(11):1023-31.
54. Hill AB. The environment and disease: association or causation? Proc R Soc Med [Internet]. 1965 May;58:295-300 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1898525/.
55. Kumar A, Roberts D, Wood KE, Light B, Parrillo JE, Sharma S, et al. Duration of hypotension before initiation of effective antimicrobial therapy is the critical determinant of survival in human septic shock. Crit Care Med. 2006 Jun;34(6):1589-96.
56. Detels R, English P, Visscher BR, Jacobson L, Kingsley LA, Chmiel JS, et al. Seroconversion, sexual activity, and condom use among 2915 HIV seronegative men followed for up to 2 years. J Acquir Immune Defic Syndr. 1989;2(1):77-83.
57. Difranceisco W, Ostrow DG, Chmiel JS. Sexual adventurism, high-risk behavior, and human immunodeficiency virus-1 seroconversion among the Chicago MACS-CCS cohort, 1984 to 1992.A case-control study. Sex Transm Dis. 1996 Nov-Dec;23(6):453-60.
58. Thavendiranathan P, Bagai A, Brookhart MA, Choudhry NK. Primary prevention of cardiovascular diseases with statin therapy: a meta-analysis of randomized controlled trials. Arch Intern Med [Internet]. 2006;166(21):2307-13 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pubmedhealth/PMH0022908/.
59. Schünemann HJ, Oxman AD, Vist GE, Higgins JPT, Deeks JJ, Glasziou P, et al. Chapter 12: Interpreting results and drawing conclusions. En: Higgins JPT, Green S, editores. Cochrane Handbook for Systematic Reviews of Interventions [Internet]. Version 5.1.0. London: The Cochrane Collaboration; 2011 [actualizado 03/2011; consultado el 15/10/2015]. Disponible en: http://handbook.cochrane.org.
60. Hoffrage U, Lindsey S, Hertwig R, Gigerenzer G. Medicine. Communicating statistical information. Science. 2000 Dec; 290(5500):2261-2.
61. Gigerenzer G, Galesic M. Why do single event probabilities confuse patients? BMJ.2012 Jan; 344:e245.
62. Akl EA, Oxman AD, Herrin J, Vist GE, Terrenato I, Sperati F, et al. Using alternative statistical formats for presenting risks and risk reductions. Cochrane Database Syst Rev. 2011 mar 16;(3):CD006776.
63. Gigerenzer G. What are natural frequencies? BMJ. 2011 Oct;343:d6386.
64. Reitsma JB, Rutjes AWS, Whiting P, Vlassov VV, Leeflang MM G, Deeks JJ. Chapter 9: Assessing methodological quality. En: Deeks JJ, Bossuyt PM, Gatsonis C, editors. Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy. Version 1.0.0. London: The Cochrane Collaboration; 2009.
65. Lopes LC, Spencer FA, Neumann I, Ventresca M, Ebrahim S, Zhou Q, et al. Bleeding risk in atrial fibrillation patients taking vitamin K antagonists: systematic review and meta-analysis. Clin Pharmacol Ther. 2013 Sep;94(3):367-75.
66. Hayden JA, van der Windt DA, Cartwright JL, Côté P, Bombardier C. Assessing bias in studies of prognostic factors. Ann Intern Med. 2013 Feb;158:280-6.
7. Busse JW, Guyatt GH. Tool to assess risk of bias in case control studies [Internet]. [consultado 02/03/2016] Disponible en: http://distillercer.com/wp-content/uploads/2014/02/Tool-to-Assess-Risk-of-Bias-in-Case-Control-Studies-Aug-21_2011.doc.
68. Randolph A, Cook DJ, Guyatt GH. Prognosis. En: Guyatt G, Rennie D, Meade MO, Cook DJ, editores. The users’ guides to the medical literature: a manual for evidence-based clinical practice. 2ª ed. New York: McGraw-Hill Medical; London: McGraw-Hill; 2008. p. 509-20.
69. Arcelus J, Mitchell AJ, Wales J, Nielsen S. Mortality rates in patients with anorexia nervosa and other eating disorders: a meta-analysis of 36 studies. Arch Gen Psychiatry. 2011 Jul;68(7):724-31.
70. Yousef F, Cardwell C, Cantwell MM, Galway K, Johnston BT, Murray L. The incidence of esophageal cancer and high-grade dysplasia in Barrett’s esophagus: a systematic review and meta-analysis. Am J Epidemiol [Internet]. 2008 Aug;168(3):237-49 [consultado 02/03/2016]. Disponible en: http://aje.oxfordjournals.org/content/168/3/237.long.
71. Oldenburg J, Pavlova A. Genetic risk factors for inhibitors to factors VIII and IX. Haemophilia. 2006 Dec;12Suppl 6:15-22.
72. Mohan KM, Wolfe CD, Rudd AG, Heuschmann PU, Kolominsky-Rabas PL, Grieve AP. Risk and cumulative risk of stroke recurrence: a systematic review and meta-analysis. Stroke . 2011 May;42(5):1489-94.
73. Glenton C, Lewin S, Carlsen B, Colvin C, Munthe-Kaas H, Noyes J, et al. Assessing the certainty of findings from qualitative evidence syntheses: the CerQUAL approach. Draft for discussion [Internet]. 2013 [consultado 10/03/2016]. Disponible en: http://www.gradepro.org/Rome2013/22acerqual.pdf.
74. Lewin S, Glenton C, Munthe-Kaas H, Carlsen B, Colvin CJ, Gülmezoglu M, et al. Using qualitative evidence in decision making for health and social interventions: an approach to assess confidence in findings from qualitative evidence syntheses (GRADE-CERQual). PLoSMed [Internet]. 2015 Oct;12(10):e1001895 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4624425/.
75. Glenton C, Colvin CJ, Carlsen B, Swartz A, Lewin S, Noyes J, et al. Barriers and facilitators to the implementation of lay health worker programmes to improve access to maternal and child health: qualitative evidence synthesis. Cochrane Database Syst Rev. 2013 Oct;10:CD010414.
Lecturas recomendadas
En este apartado se proponen como lecturas recomendadas el handbook electrónico de la herramienta GDT del grupo GRADE, en la que se inciden, entre otros aspectos, en las directrices a tener en cuenta en la evaluación y síntesis de la evidencia científica de la propuesta del grupo GRADE.
También se propone la lectura de los artículos de la serie del Journal of Clinical Epidemiology publicados por el grupo GRADE, en el que se detallan las directrices metodológicas más importantes a la hora de aplicar el marco GRADE en la evaluación y síntesis de la evidencia científica, así como los artículos publicados por el grupo en relación con aspectos específicos a considerar con las pruebas diagnósticas, las preguntas de tipo pronóstico y la evidencia cualitativa.
Las lecturas recomendadas son las siguientes
Manual sobre GRADE
• Schünemann H, Brozek J, Guyatt G, Oxman A, editores. GRADE handbook for grading quality of evidence and strength of recommendations [Internet]. The GRADE Working Group, 2013 [actualizado 10/2013; consultado 07/10/2014]. Disponible en: http://gdt.guidelinedevelopment.org/central_prod/_design/client/handbook/handbook.html.
Serie de artículos del grupo GRADE publicados en el Journal of ClinicalEpidemiology
• Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, et al. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. J Clin Epidemiol. 2011 Apr;64(4):383-94.
• Guyatt GH, Oxman AD, Vist G, Kunz R, Brozek J, Alonso-Coello P, et al. GRADE guidelines: 4. Rating the quality of evidence--study limitations (risk of bias). J Clin Epidemiol. 2011 Apr;64(4):407-15.
• Guyatt GH, Oxman AD, Kunz R, Woodcock J, Brozek J, Helfand M, et al. GRADE guidelines: 7. Rating the quality of evidence--inconsistency. J Clin Epidemiol. 2011 Dec;64(12):1294-302.
• Guyatt GH, Oxman AD, Kunz R, Woodcock J, Brozek J, Helfand M, et al. GRADE guidelines: 8. Rating the quality of evidence--indirectness. J Clin Epidemiol. 2011 Dec;64(12):1303-10.
• Guyatt GH, Oxman AD, Kunz R, Brozek J, Alonso-Coello P, Rind D, et al. GRADE guidelines 6. Rating the quality of evidence--imprecision. J Clin Epidemiol. 2011 Dec;64(12):1283-93.
• Guyatt GH, Oxman AD, Montori V, Vist G, Kunz R, Brozek J, et al. GRADE guidelines: 5. Rating the quality of evidence--publication bias. J Clin Epidemiol. 2011 Dec;64(12):1277-82.
• Guyatt GH, Oxman AD, Sultan S, Glasziou P, Akl EA, Alonso-Coello P, et al. GRADE guidelines: 9. Rating up the quality of evidence. J Clin Epidemiol. 2011 Dec;64(12):1311-6.
• Guyatt G, Oxman AD, Sultan S, Brozek J, Glasziou P, Alonso-Coello P, et al. GRADE guidelines: 11. Making an overall rating of confidence in effect estimates for a single outcome and for all outcomes. J Clin Epidemiol. 2013 Feb;66(2):151-7.
• Guyatt GH, Oxman AD, Santesso N, Helfand M, Vist G, Kunz R, et al. GRADE guidelines: 12. Preparing summary of findings tables-binary outcomes. J Clin Epidemiol. 2013 Feb;66(2):158-72.
• Guyatt GH, Thorlund K, Oxman AD, Walter SD, Patrick D, Furukawa TA, et al. GRADE guidelines: 13. Preparing summary of findings tables and evidence profiles-continuous outcomes. J Clin Epidemiol. 2013 Feb;66(2):173-83.
Lecturas sobre GRADE y pruebas diagnósticas
• Brozek JL, Akl EA, Jaeschke R, Lang DM, Bossuyt P, Glasziou P, et al. Grading quality of evidence and strength of recommendations in clinical practice guidelines: Part 2 of 3. The GRADE approach to grading quality of evidence about diagnostic tests and strategies. Allergy. 2009 Aug;64(8):1109-16.
• Gopalakrishna G, Mustafa RA, Davenport C, Scholten RJ, Hyde C, Brozek J, et al. Applying Grading of Recommendations Assessment, Development and Evaluation (GRADE) to diagnostic tests was challenging but doable. J Clin Epidemiol [Internet]. 2014 Jul;67(7):760-8 [consultado 02/03/2016]. Disponible en: http://www.sciencedirect.com/science/article/pii/S0895435614000444.
• Hsu J, Brozek JL, Terracciano L, Kreis J, Compalati E, Stein AT, et al. Application of GRADE: making evidence-based recommendations about diagnostic tests in clinical practice guidelines. Implement Sci [Internet]. 2011 Jun;6:62 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3126717/.
• Schünemann HJ, Oxman AD, Brozek J, Glasziou P, Jaeschke R, Vist GE, et al. Grading quality of evidence and strength of recommendations for diagnostic tests and strategies. BMJ [Internet]. 2008 May;336(7653):1106-10 [consultado 02/03/2016]. Disponible en: http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2386626/.
Lecturas sobre GRADE y preguntas de tipo pronóstico
• Iorio A, Spencer FA, Falavigna M, Alba C, Burnand B, McGinn T, et al. Use of GRADE for assessment of evidence about prognosis: rating confidence in estimates of event rates in broad categories of patients. BMJ [Internet]. 2015 Mar;350:h870 [consultado 02/03/2016]. Disponible en: http://www.bmj.com/content/350/bmj.h870.long.
Lecturas sobre GRADE y evidencia cualiatitva
• Glenton C, Lewin S, Carlsen B, Colvin C, Munthe-Kaas H, Noyes J, et al. Assessing the certainty of findings from qualitative evidence syntheses: the CerQUAL approach. Draft for discussion [Internet]. 2013 [consultado 10/03/2016]. Disponible en: http://www.gradepro.org/Rome2013/22acerqual.pdf.
Anexos
Anexo 6.4. Plantilla perfil de evidencia GRADE Profile
Anexo 6.5. Elaboración de perfiles de evidencia GRADE
Anexo 6.6. Herramientas QUADAS
Anexo 6.7. Tablas de evidencia GRADE para preguntas de tipo diagnóstico
Tablas y figuras
Tabla 6.1. Factores que modifican la calidad de la evidencia
Tabla 6.3. Principales fuentes de sesgo a evaluar en los estudios no aleatorizados
Tabla 6.4. Criterios para evaluar la utilización de los análisis de subgrupos
Figura 6.1. Esquema que sintetiza los contenidos del capítulo 6. Evaluación y síntesis de la evidencia científica
Figura 6.4. Tratamiento con corticoesteroides para reducir la mortalidad hospitalaria en pacientes con shock séptico
Figura 6.6. Realización del cribado de bacteriuria durante el embarazo
Figura 6.7. Criterios para valorar el riesgo de sesgo de los estudios pronósticos
Figura 6.8. Traducción de la Adaptación de la herramienta de lectura crítica CASP para estudios cualitativos


